

 融资信息
融资信息
 专题
专题
 链上生态
链上生态
 词条
词条
 播客
播客
 活动
活动

ArkStream Capital: 详解zk在扩容和隐私保护赛道的投资机会(一)

原文标题:《ArkStream Capital: 详解 zk 在扩容和隐私保护赛道的投资机会 (一)》
原文作者:Ray
原文来源:ArkStream Capital 公众号
序言
当前的比特币网络或者以太坊网络,全网都会有不少等待区块打包确定的交易。这种交易等待确认机制,极大地打击用户使用的体验,交易拥堵是整个行业现在亟待解决的问题。另外,由于区块链自身的公开透明,一旦地址被标记,我们的所有交易行为就毫无隐私可言。随着 DeFi 的发展,在这加密货币的黑暗森林里,隐私保护的需求从来没有比现在更加迫切。在 DeFi 积木濒临倒塌的时候,链上清晰可见的清算线和定点爆仓成了价格止不住下跌的重要推手。
对于网络并发容量和隐私两大难题,极客和开发者们进行了数年的探索。零知识证明技术,凭借其自身独特的性质,如同透明、去中心化和不可篡改对于区块链技术那般重要,自成体系地带来了扩容和隐私问题的解决方案。本文将从零知识证明的定义和实现方案出发,以市场上的众多热门项目为例,探讨它在扩容和隐私保护两大领域的探索,从投资机构的角度,去思考这其中的投资机会。
零知识证明的定义
人们在生活交往过程中会倾向于相信自己的所见所闻,但是,对于有价值的信息,或者说是知识,它的拥有者都会想在不泄露核心机密的同时,让其他人相信自己对知识是具有所有权的。为了解决这样的需求,零知识证明应运而生。换用更加学术化的表达,零知识证明是两方针对"知识为真"进行的证明和验证,其中知识的所有方也即证明方,另一方则对应是验证方。
我们用一张草图,直观地解释零知识证明能够实现什么。
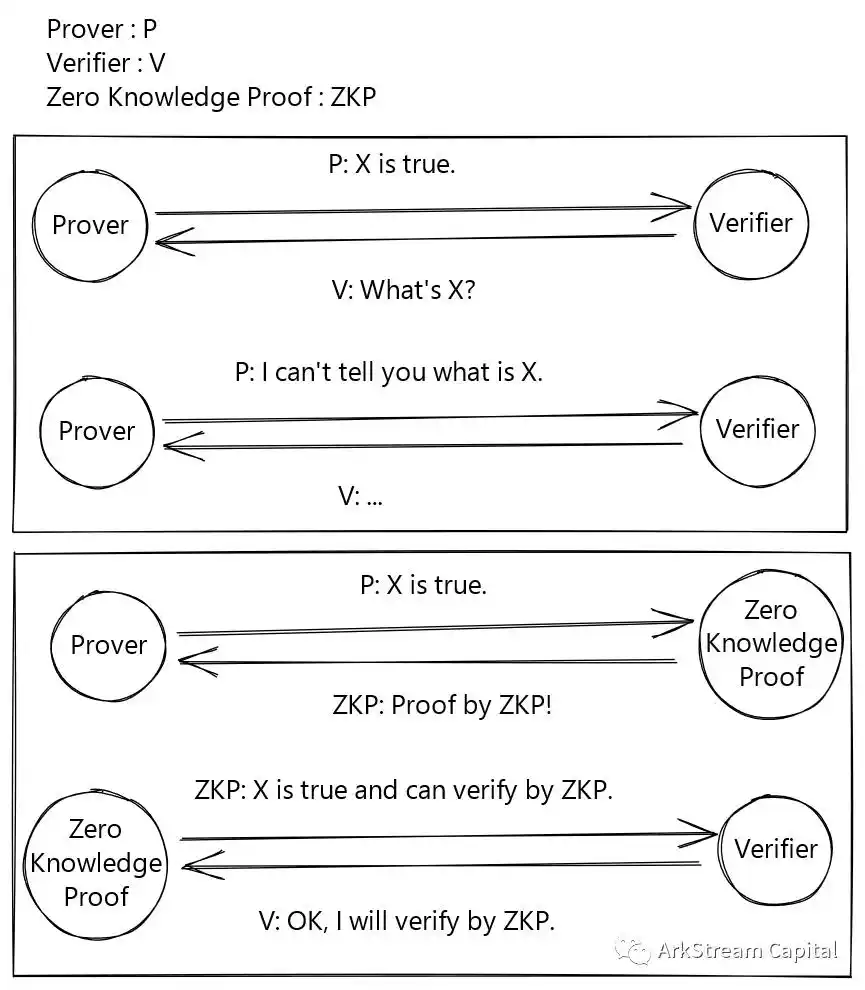
Figure 1: Proof without ZKP and with ZKP
从这张图中,我们可以提炼出零知识证明的三个性质:
完备性(Complete):诚实的证明方,对「知识为真 」这一论断进行证明,肯定可以让验证方信服。
合理性(Sound):证明方无法将「 知识为假 」证明成「知识为真」。
零知识性(Zero Knowledge):整个证明,验证方除了「 知识为真」这一论断,不会获得其他与知识相关的机密。
这三个性质用大白话讲,那就是:真的假不了;假的真不了;未知是真的,未知依然未知。第三个性质换一种更加通俗的说法,我说了「什么是真的」,你验证了「什么是真的「,但是你不知道什么是什么。
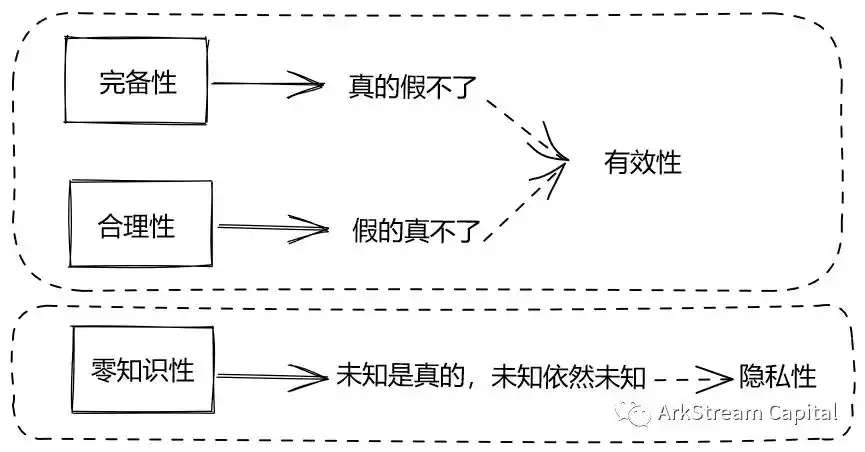
Figure 2: 零知识证明三个性质和两个特性
前面两个性质相对第三个性质容易理解和注意,而第三个性质非常容易混淆和忽略。
当证明和验证双方都知道知识的内容时候,是可以很容易地验证「知识为真」的,但是,却再也无法满足证明要求的零知识性。反之,如果满足了零知识性,我们又很难验证。试想一想,我们怎么判断证明和验证的过程中,没有泄露到任何知识内容呢?如果没有泄露到知识内容,那么验证者会相信知识是真的呢?毕竟,他连知识是什么都不知道,甚至于,可能连知识是否存在都无意识无感知!但事实是,知识必然要存在,反则,证明的「知识为真」根本无从发起!
我们用更具体的例子讲讲,例如,我们都相信中本聪肯定是存在世界的,不然,比特币就无从出现了,但是,这么多年以后,我们并不知道中本聪是否存活在世界。假如中本聪依然存活,并且,他想告诉世人他还活着。那么,中本聪可以使用零知识证明向世人传递」我依然活着」,此时世界按照零知识证明验证得知这个信息,但是并不会知道中本聪是否有使用到私钥,是否登陆当年 BitcoinTalk 的账号自证等。另一种场景是,中本聪在发明比特币的时候,创世地址是拥有第一笔比特币,当这个地址使用对应私钥进行活动的时候,同样可以传递中本聪依然活着的信息,但是这却不再满足了零知识性,因为,世人都知道中本聪依然活着,是因为他的私钥发生活动。
简单地说,零知识证明不仅可以保证知识的隐私性,也可以保证知识的有效性。这两点直接决定了零知识证明在加密世界里的两大类应用场景:隐私和扩容。当然,隐私场景会有更多细分应用,例如隐私支付、匿名投票甚至于隐私公链等,也可以通用地理解为资产支付型隐私和逻辑通用型隐私。至于扩容场景,使用的是零知识证明的完备性和合理性,以及其他技术手段共同实现的。
零知识证明的实现
零知识证明是使用很多数学和密码学知识共同协作配合发明和实现的。在整个证明的实现上面,按照交互与否,可以分为交互式证明和非交互式证明。交互式证明是证明过程需要证明方和验证方按照某种顺序和规则交替进行,然后通过随机概率完成证明。非交互式证明是证明方按照证明规则或证明过程,完整的一次性自行计算和提交所有证明资料,然后,验证方可以直接用这些证明资料进行验证。换一种极端的理解,非交互式证明是将交互式证明的多个步骤压缩到一步交互即可。另外,非交互证明可以看作将整个实现拆分成为证明过程和验证过程。
下面,我们用两个不同的场景模拟交互式证明和非交互式证明的差异。
简化场景一,假设中本聪的创世私钥重现人间,现在,要证明这个私钥依然活动。
交互式证明的流程:
1,验证方喊话创世私钥证明方,你在某个区块高度之后写下一句话:Hello World。
2,创世私钥证明方按照要求,等待某个区块高度之后,向全网留言:Hello World。
3,验证方在网络里面验证创世私钥是否按照要求在某个区块高度之后留言:Hello World。
4,重复 1、2、3 这三个步骤,当次数达到一定程度,从概率学角度可以判定,这个私钥基本是活动的。
非交互式证明的流程:
1,某个设备/模拟器/图灵机生成一个共享的、随机的字符串 xyz,然后将这个字符串公开,并且要求创世私钥证明方以「xyz,Hello World」的形式,向全网留言。
2,创世私钥证明方,按照设备/模拟器/图灵机的规则,使用这个字符串 xyz,加上自己的 Hello World,向全网留言:「xyz,Hello World」。
3,验证方拿着这个字符串 xyz,看到创世私钥的留言之后,直接判定这个私钥是活动的。
简化场景二,假设张三懂高斯算法,李四不懂。
交互式证明的流程:
1,李四喊话张三,30 秒内计算 1+2+3+...+8887+8888。
2,张三拿着高斯算法,30 秒算出结果,并告诉李四。
3,李四用自己最朴素的加法检验结果是否正确。
4,重复 1、2、3 这三个步骤,当次数达到一定程度,从概率学角度可以判定,张三懂高斯算法。
非交互式证明的流程:
1,某个设备/模拟器/图灵机生成一个共享的随机的整数 x。
2,张三拿着高斯算法,直接计算 1+2+3+...+(x-1)+x 的结果。
3,李四用自己最朴素的加法检验结果是否正确,若正确,张三懂高斯算法。
通过上面的例子,我们可以发现,非交互式证明比交互式证明有明显的优势:1,不依赖于特定的交互验证方,是 1 个证明方对 N 个验证方的极佳方案;2,不局限于交互时刻,可以随时进行。但是,我们也注意到非交互式证明里面多了模拟器/图灵机的存在!
这里,就引出了零知识证明的核心概念:模拟器/图灵机。模拟器/图灵机可以隐藏知识,但是依然保证「知识是真」可以顺利进行证明和验证。
为了实现非交互式证明的模拟器/图灵机核心功能,现在的技术方案大概有:随机预言(Random Oracle)和公共参考串(Common Reference String、CRS),而其中公共参考串是广泛使用的方案。我们认为,随机预言和公共参考串没有太大本质的差别。公共参考串 CRS 必须由一个受信任的第三方进行生成,然后共享给证明方和验证方。这里,CRS 的生成必须保证随机可信,因此,产生 CRS 的环节也称为可信设置,Trusted Setup。
我们可以用神来比喻模拟器/图灵机,神是公立的,不仅可以帮助证明者隐藏知识,协助证明者完成证明,也可以辨识证明者是否伪造知识,协助验证者顺利验证。神是完美无缺的,但终归需要人去创造神,创造神的过程可以对应为:可信设置。另外,神是存在适用性的,也不一定是通用的,就像耶稣是西方的神,如来是东方的神(可信设置的适用性)。再往深的想,神也有可能不靠谱。(可信设置的安全性)
一切的证明始终得回到具体步骤。正如我们在解答数学证明题一样,也有答题步骤。对于零知识证明来说,这个具体步骤有专业的术语:电路(Circuit)。至于 QAP/QSP,布尔电路和算数电路,我们都简单粗暴地将它归为非交互式证明过程中的具体步骤即可。世间数学证明题千千万,解题证明的时候,都需要编写对应的解题步骤。同理,对于不同知识下面的零知识证明,电路也是需要专门编写的。当然,也有某类知识的证明可以通过共用电路框架简化编写的过程。对于不同的数学证明题,我们要写出单独的答题步骤(专用电路),而某一类数学证明题,我们可以写出通用的答题步骤(通用电路),甚至,有一类题目,我们可以直接引用另一类题目已经写好的答题步骤/结论。(电路的可组合性/交互性)。
顺着前面的数学证明题讲讲电路的位置

Figure 3: 电路的类比
至于其他的概念或者术语,例如一阶约束系统 R1CS、NP 问题、多项式、多项式的知识、因式分解、模糊计算、信息、知识、电路可满足性、完全安全、语义安全、不可区分性、映射、同态、有限域、循环群、Fiat-Shamir 变换、ECDSA 签名...... 由于涉及到太过概念和数学计算,除非是数学和密码学专家,不建议花费过多脑力和精力在这方面。我们只需要知道的关键信息是:不同的零知识证明实现方案在于可信设置的引入与否、可信设置的适用性以及电路的编写难易。
对于不同的零知识证明实现方案而言,我们可以用证明方和验证方的时间开销和空间开销,以及安全性,这五个维度是判定实现方案的优劣。
证明方的时间开销:也即计算时间,决定证明的快慢;
验证方的时间开销:也即验证时间;
证明方和验证方的空间开销:存在证明大小的概念,决定存储的空间使用要求,也是常说的简洁性所指;
安全性:由于部分的协议需要引入可信设置,对应的实现方案在安全性方面会依赖可新设置。另外,可信设置也存在适用性的差异,也就是「永久型」和「一次型」之分。
实现方案的不同,最终分成了零知识证明的两大派系协议:zk-SNARK 零知识简洁非交互式知识论证和 zk-STARK 零知识可扩展透明知识论证。
zk-SNARK:Zero-Knowledge Succint Non-interactive Arguments of Knowledge。非交互式证明、需要可信设置,不同的实现方案在可信设置方面要求和效果也不一样。从 ZCash 开始采用发展多年,并且有很多细分的优化实现方案,知名的项目有:ZCash、zkSync、Aztec 等,因为时间较长,又诞生出大量的衍生协议:Schnorr 协议,Pinocchio 协议、Marlin 协议,Sonic 协议,Libra 协议,PLONK 协议、Spartan 协议、BullteProof 协议等。
zk-STARK:Zero-Knowledge Scalable Transparent Argument of Knowledge。非交互式证明、不需要可信设置,抗量子计算、证明大小开销很大。Starkware 团队发明和提出,有一些专用型的项目在应用,dYdX(近期宣布迁移到 Cosmos)、Immutable 和 Deversifi。
参考区块链不可能三角的说法,零知识证明的实现方案可以说是不完美三角,所有的实现方案虽然可以同时实现完备性、合理性和零知识性,但因为应用场景的要求,都是有某方面的取舍。或者更明显的情况是,侧重完备性和合理性时,零知识性的实现会弱化,甚至可能忽略(扩容 Layer2)。另外,零知识证明本身是没有去中心化的属性,如果这方面有要求,需要结合去中心化的设计(难上加难)。
零知识证明的虚拟机
在探讨实现方案的不同后,我们接下来探讨方案落地的关键。现在互联网的应用和产品都是采用高级编程语言(C++,Java,Rust,Solidity......)实现的程序。虚拟机/解释器是程序执行的黑盒子,可以将程序转换成为机器可以识别和理解的语言,然后代替机器运行程序。如果没有零知识证明的虚拟机,我们在使用零知识证明技术编写程序的时候,需要专门为程序编写对应的实现电路。这类电路的编写、测试和生产使用是非常困难和低效的。为此,要让零知识技术的使用更加广泛和高效,可以为程序生成证明的提交和验证的零知识证明版虚拟机(zkVM)就是必然需要的。至于 zkVM 采纳的高级编程语言到底是 C++、Java 还是专门设计的电路编程高级语言(Stareware 的 Cairo、zkSync 的 Zinc),这些取决于 zkVM 的设计和能力。需要强调的是,zkVM 是没有硬性使用区块链的要求的。
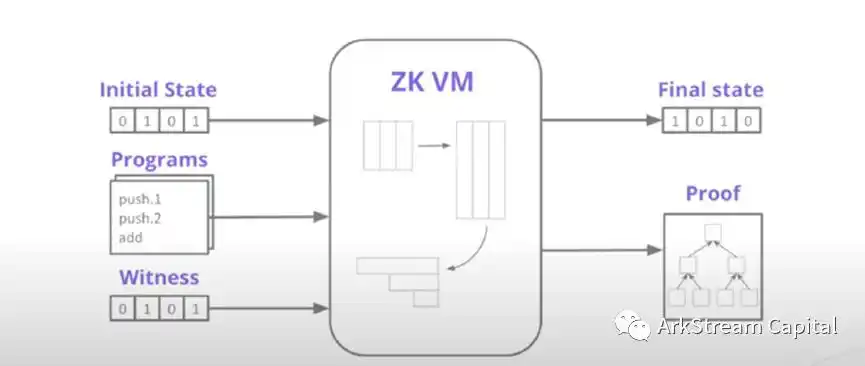
Figure 4:Polygon Miden Deep Dive zkVM
对于 zkVM 而言,可以通用地支持程序是非常重要的,如果只能完成某类程序的虚拟机化,那这种 zkVM 的通用性将大打折扣。除了通用性以外,简洁性、递归可用性、可组合性和易用性都是其他需要考量的指标。
这里主要举例说明下递归可用性:
问题:假设计算机只支持两位数相加,不支持多位数相加和相乘,计算 1+2+3+...+99+100?
非递归版解决:
1+2=3,3+3=6,6+4=10,...,4950+100=5050
总共执行了 99 次相加。(这里不引入迭代的概念,感兴趣的自行搜索学习)
递归版解决:
1+2+3+...+99+100
计算 1 和(2+3+...+99+100) 的和即可,至于(2+3+…+99+100)的计算可以重新使用这种方法去解决,也就是 (2+3+...+99+100) 转换为计算 2 和 (3+...+99+100),如此循环以至符合两位数相加的限制条件,即 99+100 = 199,然后用 199 去结束递归,算出结果。
递归可用性可以在解决问题的时候,直接重复使用解决问题的方案。这可以大大简化实际问题的解决思路。
前面我们提到 zkVM 的使用和区块链没有硬性关联,所以,接下来,我们会尝试探索 zkVM 和区块链的结合。首先,让我们回到以太坊,这台创新性提出智能合约的世界计算机,或者更技术范地说,分布式的虚拟机。广义的 EVM(Ethereum Virtual Machine),可以等同于以太坊,包含的模块有可变的机器状态、只读的 EVM 代码、存储的账户数据。狭义的 EVM,可以指代以太坊虚拟机的只读 EVM 代码和 EVM 操作码。
对于以太坊而言,全网在任何时刻都维护达成共识状态的主链,这条主链由最长区块进行决定。区块里面的交易将会驱动以太坊的世界状态发生变化。我们在抱怨网络的交易吞吐量不够以及隐私不足的时候,实际根源正是以太坊内部组件自身的瓶颈和缺陷。此刻,让我们进行无比美好的憧憬,如果整个以太坊的所有模块都可以进行零知识证明化,那么交易的执行计算不再需要由以太坊进行处理,以太坊单纯只需要完成交易有效性的验证即可,并且,以太坊内部账号数据,可以根据需要选择性地公开透明。这样一来,以太坊的交易处理能力可以得到大大地释放,链上数据的隐私能力也得以保证。配合当下零知识证明实现的多样性,以太坊不用局限于某一类零知识证明的实现,可以兼容性地支持各个主流零知识证明的实现,保持自身的开放性和扩展性。
理想是美好的,但是事实总是骨感,甚至是残酷的。以太坊在创立时候,是没有考虑引入零知识证明的,所以,如果以太坊直接零知识证明化,将带来最大的问题是,以太坊协议的大部分组成将会导致大量的零知识证明计算,这在本质上面并没有发挥零知识证明的优势。当然,以太坊协议本身是可以随着时间和技术的发展发生迭代更新的。如同 PoW 转成 PoS 这种划时代性的共识机制变化,以太坊协议的零知识证明化在未来是有可能通过以太坊升级达成的。
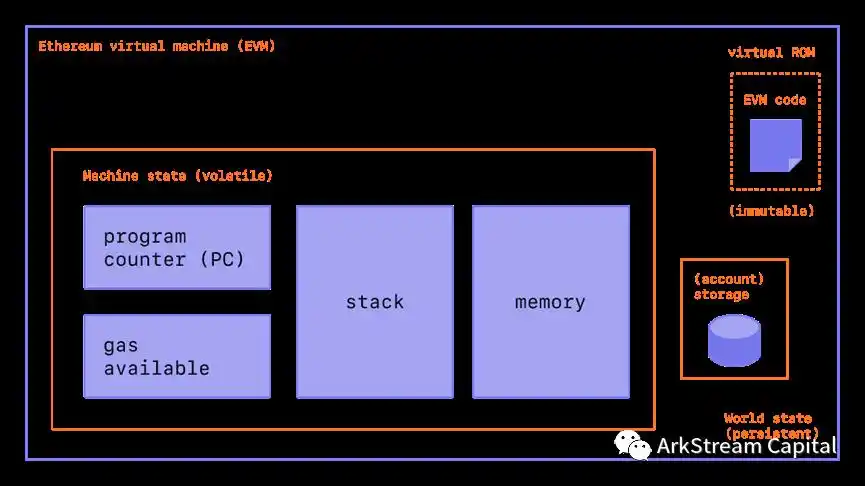
Figure 5: ETHEREUM VIRTUAL MACHINE (EVM)
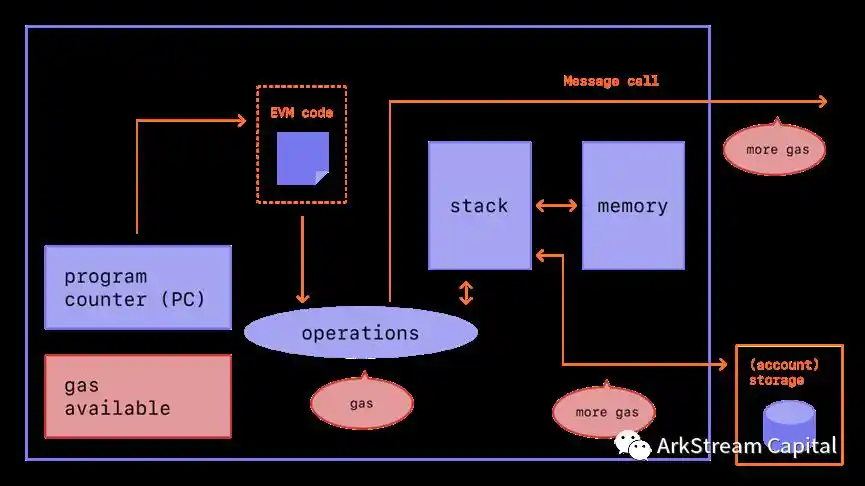
Figure 6: ETHEREUM VIRTUAL MACHINE (EVM)
2022 年 8 月 4 日,以太坊创始人 Vitalik 发布文章:《The different types of ZK-EVMs》。该篇文章与此前 Scroll 团队、以太坊研究员 Justin Drake 提出的以太坊 EVM 分类有异曲同工之妙。我们可以从下面几张图更清晰地理解这些 zkEVMs/zkVMs 的设计和优缺点。
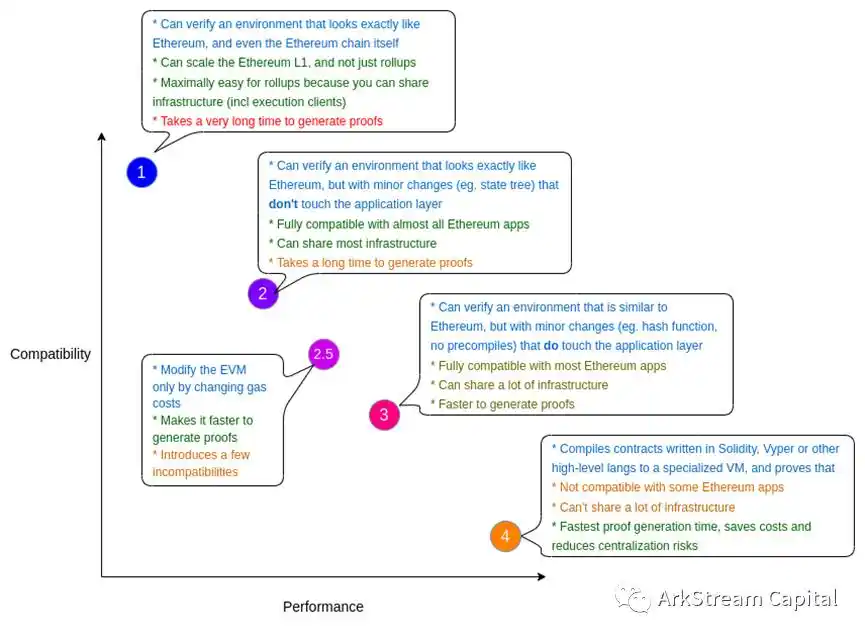
Figure 7: The different types of ZK-EVMs

Figure 8
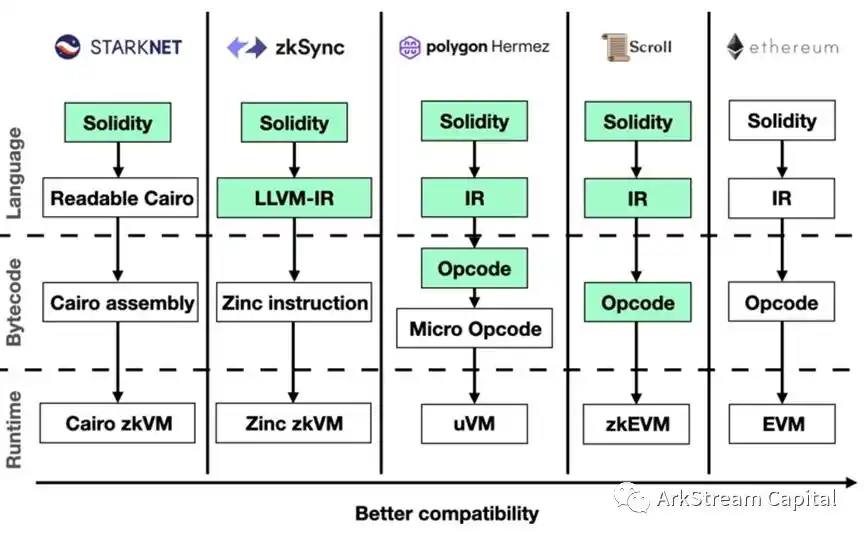
Figure 9
现在,让我们简单汇总整个 zkVMs/zkEVMs 技术的团队或项目的进展。
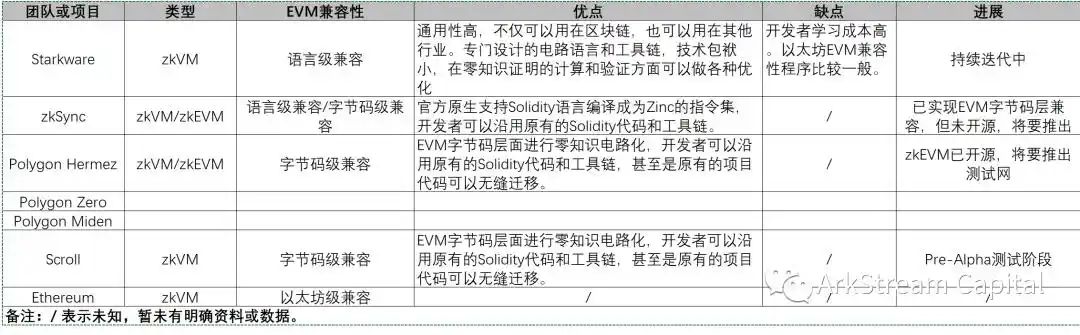
Figure 10
zkVM 和 zkEVM 的研究和实现,面临的实现难题不尽相同,也没有先后依赖顺序,因此是可以同步并行推进。具体到设计挑战和解决方案,可以参考各家项目的资料和文档。不同项目的对于 zkVM/zkEVM 选择肯定有自己的考量,目前看来,大部分都会倾向优先 zkEVM 道路,毕竟以太坊扩容的刚需场景一直存在。另外,以太坊本身终极 ZK 目标是,全部兼容。这么一想,基于 zkEVM 进行研发的项目,未来或许都会进化成多样的以太坊轻节点客户端。至于 zkVM,我们只能说,区块链必然是它行进的伙伴,但它远方的梦想也不止于区块链。
参考资料:
[1] https://github.com/sec-bit/learning-zkp/blob/master/zkp-resource-list.md 零知识证明学习资源汇总
[2] https://mp.weixin.qq.com/s/808jMXvIUqB973aVHrAzGQForesight Ventures:解读 zk、zkVM、zkEVM 及其未来
[3] https://www.odaily.news/post/5178462Scroll 研究:zkEVM 的设计挑战和解决方案
[4] https://www.odaily.news/post/5177903LD Capital:一文纵览 ZK 方案全明星项目
[5] https://mirror.xyz/cvalleylive.eth/Deag4YB_EYHaTDv0lc5iPhLpWxzMLG1tyC2GSTwJE4k 万字硬核解读:ZK 为什么重要?
[6] https://ethereum.org/en/developers/docs/evm/Ethereum Virtual Machine
欢迎加入律动 BlockBeats 官方社群:
Telegram 订阅群:https://t.me/theblockbeats
Telegram 交流群:https://t.me/BlockBeats_App
Twitter 官方账号:https://twitter.com/BlockBeatsAsia








 0
0