

 Forum
Forum Finance
Finance
 Specials
Specials
 On-chain Eco
On-chain Eco
 Entry
Entry
 Podcasts
Podcasts
 Activities
Activities
 OPRR
OPRR

Ethereum merger, what should be paid attention to when running the client?
Original title: "Ethereum Merger: Running a Dominant Client? Do it at your own risk! "
Original author: Dankrad Feist, Ethereum Foundation
Original compilation: Nanfeng, Unitimes
For security and reactivity considerations, Ethereum chose a multi-client architecture. To encourage diversification in the client setup of stakers, the Ethereum protocol has higher penalties for correlated failures. Thus, a staker running a client with a minority market share will typically lose only a modest amount if the client bugs, whereas a staker running a client with a dominant market share will typically lose only a modest amount. client, then the pledger may lose all the pledged money when the client encounters a bug. Therefore, responsible stakers should look at the current client distribution landscape and choose to run a less popular client.
01. Why do we need multiple clients?
There are many arguments that a single client architecture is preferable. Developing multiple clients comes with a huge overhead, which is why we haven't seen any other blockchain network seriously pursue offering multi-clients.
So, why is Ethereum targeting a multi-client architecture? Clients are very complex code and may contain bugs. The worst of these are so-called “consensus bugs,” bugs in blockchain core state transition logic. An oft-cited example is the so-called "infinite money supply" bug, where a client with this bug will accept (approve) a transaction that mints any amount of ETH. If someone finds this bug in a client and is not stopped before the person reaches a safe exit (i.e. through a mixer or exchange to spend the funds), it will cause a significant drop in the value of ETH .
If everyone was running the same client, stopping this would require manual intervention, because in this case the blockchain, all smart contracts and The exchange will operate as usual. An attacker might even take only a few minutes to successfully launch an attack and spread the funds sufficiently that it would be impossible to just roll back the attacker's transaction. Depending on the amount of ETH minted, the Ethereum community will likely coordinate a rollback of Ethereum to its state prior to this attack (this would need to be done after the bug was identified and fixed).
Now let's see what happens when we have multiple clients. There are two possible scenarios:
1. The client containing the bug hosts less than 50% of the total network deposit. The client will produce a block that includes a transaction that exploits the bug to mint ETH. Let's call this chain the A chain.
However, the vast majority of stakers running another client that does not have the bug will ignore the block because it is invalid (for the As far as the client is concerned, the operation of casting ETH is invalid). Therefore, the stakers (validators) running this client will build another chain, let's call it the B chain, which does not contain this invalid block.
As the correct client dominates, the B-chain will accumulate more attestations. So even that client with the consensus bug will vote for chain B; as a result, chain B will accumulate 100% of the votes and chain A will die. The blockchain will keep going as if the bug never happened.
2. The vast majority of stakers use this buggy client. In this case, Chain A will accumulate a majority of votes. But since chain B has less than 50% proofs, that buggy client will never have a reason to switch from chain A to chain B. Therefore, we will see blockchain splits. As shown below:
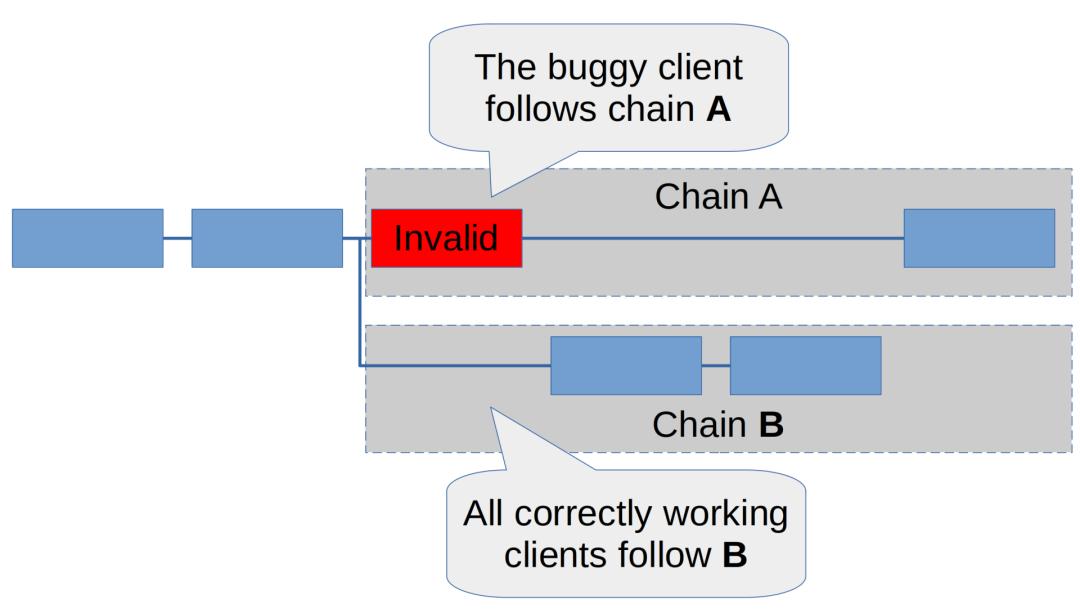
The first situation above is ideal. This situation is likely to produce an orphaned block, which will not be noticed by most users. The developer can debug the client, fix the bug, and everything is fine. The second case is obviously not ideal, but it is still a better result than having only one client in total (i.e. a single client architecture), and most people will quickly find that with a forked chain (You can automatically detect this by running a few clients), exchanges will suspend deposits soon, and DeFi users can also proceed with caution until the chain split is resolved. Basically, this still gives us a big blinking red light compared to a single client architecture, allowing us to be protected from the worst possible outcomes.
In the second case above, if the buggy client is run by more than 2/3 of the stakers, then the situation will be even worse, Because the client will finalize the invalid chain (namely A chain). We will elaborate more on this below.
Some argue that chain splits are so catastrophic that this is itself an argument in favor of a single-client architecture. Note however that the chain split only happened due to a bug in the client. In terms of single-client architecture, if you want to fix the bug and return the blockchain to its previous state, you have to roll back to the block before the bug happened, which is as bad as a chain split! So, in terms of multi-client architectures, although chain splits sound bad, chain splits are actually a feature, not a bug, in the case of critically buggy clients. At least you know something serious is wrong.
02. Incentivizing client diversity: anti-relevance penalties
If the validator's The deposit is distributed among multiple clients, which is obviously beneficial to the network, and the best case is that each client holds less than 1/3 of the total deposit. This will make the network resilient in the face of any single client bug. But why should stakers care about this? If the network does not have any incentives for stakers, it is unlikely that they will be willing to incur the cost of switching to another minority client.
Unfortunately, we cannot reward validators directly based on which client they choose to run. There isn't an objective way to measure this.
However, when you run a client with a bug, you are not immune. This is where anti-correlation penalties (anti-correlation penalties) come into play: the idea is that if you run a validator that behaves maliciously, then you will be penalized because there are more other validators in the network. Around the same time made a mistake and got higher. In other words, you get penalized for associativity failures.
In Ethereum, you (the verifier) will get slashed for two actions:
1. Sign two blocks at the same block height.
2. Create slashable proofs (surround voting or double voting).
When you (the validator) get slashed, you usually don't lose all your funds. At the time of writing (beacon chain Altair fork), the default penalty is actually very small: you will only lose 0.5 ETH, or about 1.5% of your 32 ETH staked (eventually this will increase to 1 ETH , or 3%).
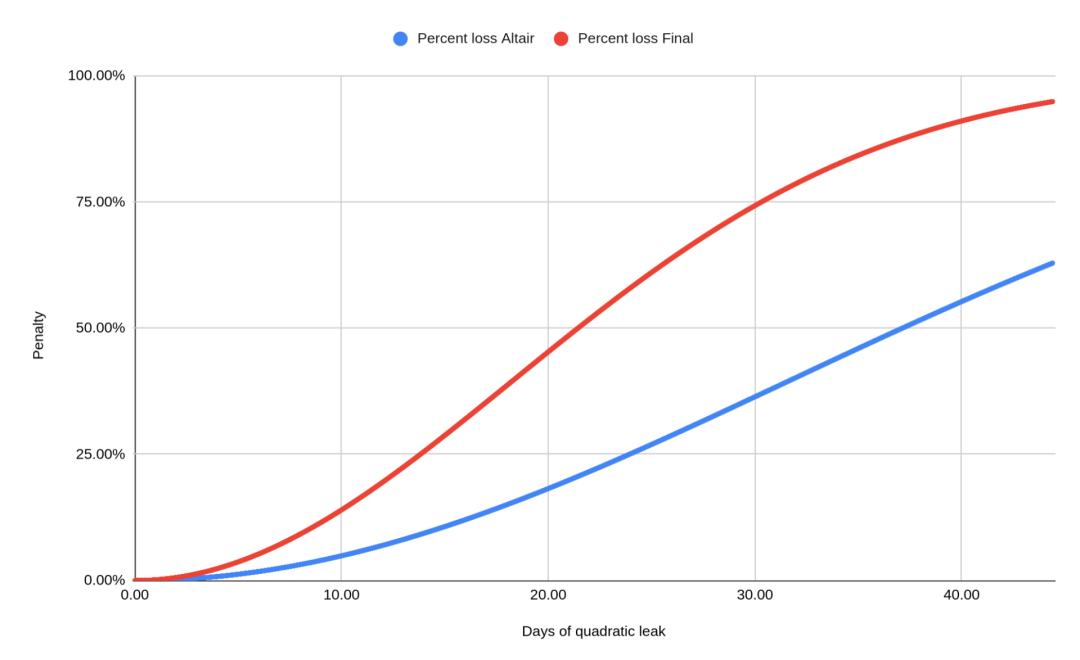
However, there is a catch here: there is an additional penalty that depends on the 4096 epochs (about 18 days) before and after your validator is slashed All other slashing events within the time period. During this period, you will be forfeited in proportion to the total amount of these forfeitures. This can be much greater than the original penalty. Currently (the Beacon Chain Altair fork) is set up so that if more than 50% of your total stake is slashed during this period (18 days before and after you are slashed), then you will lose all of your funds. Ultimately, this will be set so that if 1/3 of stakers are slashed, then you lose all of your stake. It is set to 1/3 because this is the minimum amount of deposit required to cause a consensus failure. As shown below:
Above: the blue line indicates the current (after the beacon chain Altair upgrade) penalty; the red line indicates the penalty that will eventually be set.
Another anti-correlation penalty: Quadratic Inactivity Leak
Another validator failure One way is offline. Validators are also penalized for being offline, but the mechanism is very different. We do not refer to this penalty as "slashing", and the penalty for being offline is usually mild: under normal operations, validators who are offline would be penalized in the same amount as they passed the correct The rewards that could have been obtained for ground verification are comparable. At the time of writing, validators earn 4.8% per annum. If your validators are offline for a few hours or days (e.g. due to a temporary internet outage), then there is probably nothing to stress about.
However, when more than 1/3 of the validators are offline, the situation becomes completely different. At this point, the beacon chain will not be able to finalize blocks, which threatens a fundamental property of the consensus protocol, liveness. In such a scenario, to restore the activity of the beacon chain, the so-called "quadratic inactivity leak" mechanism is used. If a validator continues to go offline while the blockchain stops finalizing, the penalty to that validator increases quadratically over time. Initially this penalty is very low; after about 4.5 days, validators who go offline lose 1% of their stake. However, after about 10 days, 5% of the stake will be lost, and after about 21 days, 20% of the stake will be lost (these are the values set by the current beacon chain Altair, and these values will double in the future). As shown below:
This mechanism is designed to allow the blockchain to recover as quickly as possible in the event of a catastrophic event that takes a large number of validators offline Finalize blocks. When offline validators lose more and more of their deposits, they will gradually be kicked out of the network, thus making up a smaller and smaller share of the total number of validators. When these offline validators' deposits are reduced to less than At 1/3 of the total network stake, the remaining online validators will regain the 2/3 majority required for blockchain consensus, allowing them to finalize the blockchain.
However, there is another case related to this: In some cases, validators can no longer vote on valid chains because they accidentally lock themselves in an invalid chain. We explain this further below.
03. How bad is it to run a dominant client?
To understand the danger, let's look at three types of failure events:
- Massive slashing events: due to a bug, validators running the dominant client (ie the one most validators choose to use) will sign slashable events.
- Mass offline event: Due to a bug, all validators running the dominant client went offline.
- Invalid block event: Due to a bug, all validators running the dominant client attested to an invalid block.
There are other types of massive failures and slashes that can happen, but I'm limiting myself to those related to client bugs (these are your should be considered when choosing which client to run).
Scenario 1: Dual Signing
This is probably what most validator operators are most worried about case: A bug caused validator clients to sign slashable events. An example of this is two attestations voting for the same target epoch, but with different payloads (this is known as "Double Signing"). Since this is a client bug, not just one staker needs to worry, but all stakers running this particular client need to worry. When this behavior is discovered, the slashing will turn into a bloodbath: all stakers involved will lose 100% of their stake. This is because what we consider here is that these stakers are running a dominant client (that is, the client that most stakers choose to use); 10% of the deposit (that is, the client is not the dominant client), then "only" about 20% of the relevant deposit will be slashed (this is the slashing strength since the Beacon Chain Altair upgrade; when the final penalty parameters take effect , this percentage would increase to 30%.)
The losses from this scenario are obviously extreme, but I also think it is highly unlikely Yes. Satisfying the conditions to be a slashable proof is simple, which is why validator clients (VCs) are built to enforce them. A validator client is a small, well-audited piece of software that Vulnerabilities of this magnitude are unlikely.
We've seen a few slashing cases so far, but as far as I can tell, they're all Due to operator misconduct - almost all of these were due to the operator running the same validator in multiple locations. Since these are non-related actions, the amount of slashing is small.
Scenario 2: Large-scale offline event
For this scenario, we assume that there is a bug in the dominant client. When triggered, it will cause the client to crash. An illegal block has been integrated into the blockchain. Whenever the dominant client encounters the block, the client will be offline, making it unable to participate in any further consensus. Since the dominant client is now offline, the Inactivity Leaks penalty kicks in.
Client developers will be scrambling to get everything back OK. In fact, in a few hours, at most a few days, they will release a bug fix to eliminate the crash. In the meantime, stakers can also choose to simply switch to another client. As long as there is enough stake or switch to another client such that more than 2/3 of the validators are online, the quadratic inactivity leak penalty will stop. It is not impossible for this to happen until the buggy client is fixed.
This scenario is not impossible (bugs that cause client crashes are the most common type of bugs), but the total amount of penalties resulting from this may be less than the 1% of the affected deposit.
Scenario 3: Invalid block
For this In this scenario, we consider a situation where the dominant client has a bug that causes the client to produce an invalid block and accept it as valid—that is, when using this When the validators of the dominant client see this invalid block, they will consider it a valid block and attest (vote for) the block.
We will call this chain containing this invalid block the A chain. Once the invalid block is produced, two things will happen:
All other healthy clients will ignore the invalid block and A separate blockchain is built on top of the valid block headers of the blockchain, which we call the B-chain. All healthy clients will vote for chain B and continue to build this chain. As shown below.
The buggy dominant client will treat both chain A and chain B as valid chains. Therefore, the client will vote for whichever chain it considers to be the "heaviest" at the moment.
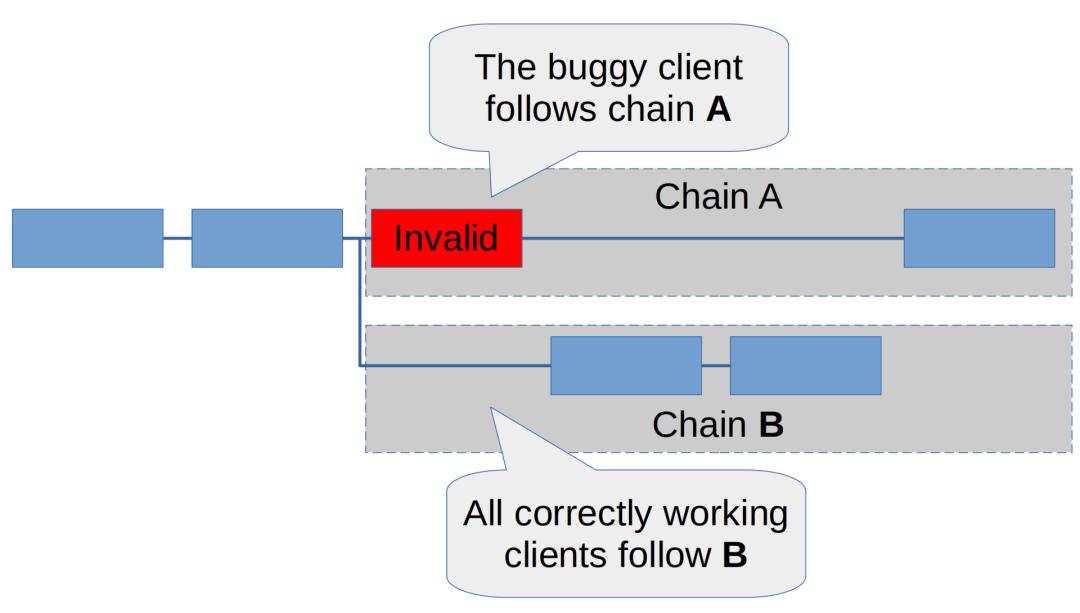
We need to distinguish three situations:
1. This has The dominant client of the bug hosts less than 1/2 of the total deposit. In this case, all other healthy clients will vote for the B chain and continue to build the B chain, eventually making the B chain the heaviest chain. At this point, even this buggy client will switch to the B chain. Nothing bad will happen except that one or a few orphan blocks will be produced. This is a happy situation and why it is important to have clients other than the dominant client in the network.
2. This buggy dominant client hosts more than 1/2 but less than 2/3 of the total deposit. In this case, we will see two chains being built - chain A built by this buggy client, and chain B built by other clients. Neither chain has an absolute dominance of 2/3 validators, so neither chain can finalize blocks. When this happens, developers will scramble to understand why there are two chains. When they find an invalid block in chain A, they can go ahead and fix the buggy dominant client. Once the bug fix is complete, the client will treat chain A as an invalid chain and start building chain B so that running chain B can achieve block finalization.
For users, this block is very destructive. While the time it takes to figure out which chain is valid is expected to be short (probably less than an hour), it is likely that the blockchain will fail to finalize a block for several hours (or even a day). But for stakers, even those running this buggy dominant client, the penalty is relatively small: they will be penalized for building an invalid A-chain instead of participating in the B-chain consensus. Penalized by "inactivity leak", but since this is likely to last less than a day, the corresponding penalty may be less than 1% of the deposit.
3. This buggy dominant client carries more than 2/3 of the deposit. In this case, the buggy dominant client will not only build the A-chain, but actually have enough stake to "finalize" the A-chain. It is important to note that this client is the only one that considers Chain A finalized, while all other functioning clients view Chain A as invalid. However, due to the way the Casper FFG protocol works, when a validator finalizes chain A, that validator will no longer be able to participate in another chain that conflicts with chain A without being slashed, unless this Chains can be finalized.
So once chain A has been finalized, validators running this buggy client are in a dire predicament: they have already voted for A chain, but chain A is an invalid chain; they also cannot build chain B, because chain B cannot be finalized yet.
Even a bug fix to their client won't help them since they've already sent offending votes. What's going to happen now is very painful: chain B that can't finalize a block will trigger an Inactivity Leak penalty mechanism, and validators on chain A will lose their stake in the next few weeks until there is enough stake The gold is destroyed, allowing the B-chain to resume finalization. Assuming that the stakers on chain A start out with 70% of the stake in the network, they will lose at least 79% of the stake, because this is the amount of their stake that needs to be reduced to represent less than 1/3 of the network The amount of pledge that must be lost. At this point, the B chain will resume finalization, and all pledges can be switched to the B chain. The blockchain will be healthy again, but not before this disruption will last for weeks, with millions of ETH burned in the process.
Obviously, the third scenario above is a disaster. This is why we very much prefer not to have any single client own more than 2/3 of the total deposit. This way invalid blocks are never finalized and this catastrophe never happens.
04. Risk Analysis
So how should we evaluate these situations? A typical risk analysis strategy is to assess the likelihood of an event occurring (we use a number of 1 for extremely unlikely and a number of 5 for quite likely) and impact (number 1 for very low and number 5 for catastrophic). The most important risks are those that score high on these two metrics, represented by the product of impact and likelihood.

Based on the table above, scenario 3 is by far the riskiest. When a client has an absolute majority of 2/3 of the deposit, this is a rather catastrophic situation, which is also a relatively likely situation. To underscore how easy such bugs can be, a similar bug occurred recently on the Kiln testnet: in this case, the Prysm client did propose a block only to find out it was wrong, and did not prove that the block piece. If at the time the Prysm client saw the block as a valid block, and if this happened on the Ethereum mainnet (rather than the testnet), then we would have the third case in Scenario 3 - because the Prysm client The terminal currently has an absolute majority of 2/3 in the Ethereum mainnet. Therefore, if you are currently running the Prysm client, there is a very real risk that you could lose all your funds and you should consider switching clients.
While Scenario 1 above is probably the most worrying scenario, it has a relatively low risk rating. The reason is that I think the probability of Scenario 1 happening is very low, because I think the validator client software is well implemented in all clients, and it is unlikely to produce slashable proofs or zones. piece.
If I am currently running a dominant client and have concerns about switching clients, what are my options?
Switching clients can be a major undertaking. It also comes with some risks. What if the slashed database was not properly migrated to the new setup? There could be a risk of being slashed, which completely defeats the purpose of switching clients.
For those worried about this kind of problem, I also suggest that there is another option: you can leave your authenticator settings as is (without taking out keys, etc. ), just switch the beacon node. This is extremely low risk because as long as the validator client works as expected, it will not be double-signed and therefore not slashed. Especially if you run a large validator business, making changes to validator client (or remote signer) infrastructure expensive and potentially subject to auditing, then this might be a good option. If the new setup doesn't perform as well as expected, it's easy to switch back to the old client, or try switching to another non-dominant client.
The advantage of this is that you have very little to worry about when switching beacon nodes: the worst thing this can do to you is being temporarily offline. This is because beacon nodes themselves can never generate slashable messages on their own. If you are running a non-dominant client, you cannot face scenario 3 above, because even if you vote for an invalid block, the block will not get enough votes to be finalized.
What about executing the client?
What I wrote above applies to consensus clients, including Prysm, Lighthouse, Nimbus, Lodestar, and Teku, as of this writing, Prysm probably has an absolute majority of 2/3 on the network.
All of these apply in the same way to the executing client. If go-ethereum (which is likely to become the dominant execution client after the merger) produces an invalid block, then the block may be finalized, thus resulting in the scenario 3 described above catastrophic situation.
Fortunately, we now have 3 other execution clients in production-ready: Nethermind, Besu, and Erigon. If you are a staker, I highly recommend running one of these execution clients. If you're running a non-dominant client, the risk is pretty low! But if you are running a dominant client, then you are at serious risk of losing all your funds!
Editor's Note: This translation has been abridged
Original link
Welcome to join the official BlockBeats community:
Telegram Subscription Group: https://t.me/theblockbeats
Telegram Discussion Group: https://t.me/BlockBeats_App
Official Twitter Account: https://twitter.com/BlockBeatsAsia






