Forum
Forum Finance
Finance
 Specials
Specials
 On-chain Eco
On-chain Eco
 Entry
Entry
 Podcasts
Podcasts
 Activities
Activities
 OPRR
OPRR

Celestia: How to ensure the integrity of message retrieval results

How Celestia ensures the integrity of message retrieval results
原文作者: Hoyt,W3.Hitchhiker
Reasons for writing this article:
Thanks to the Celestia white paper on the use of "Merkertrees with namespaces", the text is quite complex and we spent a lot of time reading, looking at open source sample code and talking back and forth with the authors before reaching an agreement. As a translator, we cannot change the structure of the original text too much. Therefore, in order to make it easier for you to understand, we consider a separate article to introduce the relevant content to you in a more concise way.
Origin of the problem:
To expand the chain's capacity, Celestia promises that sovereign apps will download only the messages associated with them (the difference between messages and transactions is that a transaction is a message that changes the state of an application) rather than the whole thing, but that messages from different apps will be bundled together in the same block to achieve equal security. So how do you ensure that when an application's execution node queries a message to Celestia's storage node, the storage node only returns all the relevant messages, and that the malicious storage node cannot hide certain messages (note that this is a different concept from data availability, which is a light client that doesn't download all the data, How to ensure that data can be downloaded by the validation node).
Celestia's preferred approach is to insert application identifiers, called namespaces, into the node information in the Merkel tree of messages. The advantage of this method is that the storage node can handle the case that all related messages are hidden, and the hidden messages can be located. In addition, the merkle tree generation logic does not need to be drastically modified to ensure that there is a node whose underlying leaf node contains, and only all messages for a namespace, and that node can be located. There are three relatively simple things you can do to ensure that the basic properties of merkle trees do not change:
First, before generating a Merkle tree of messages, the messages are grouped together by namespace, ensuring that messages from different namespaces are not interspersed and that namespaces are sorted.
Second, modify the hash function used to generate the Merkle tree so that the namespace information is included in the node information (since it is not a leaf node, the hash is the only information).
When checking merkle trees, make an extra check to see if the order is correct.
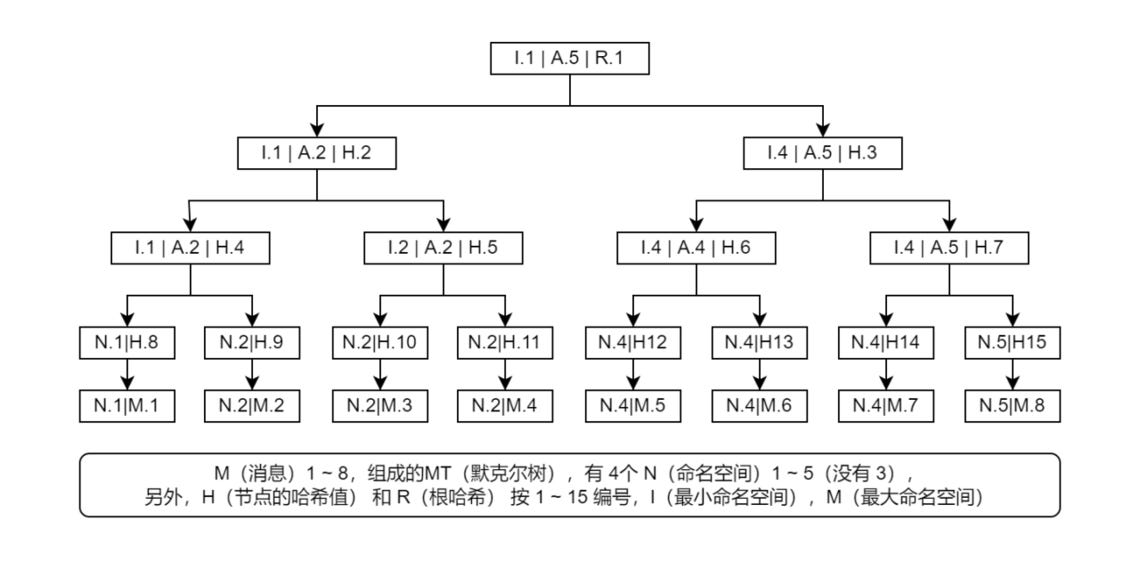
Generate merkle tree with namespace:
As we said earlier, only the function that generates the hash of the node differs from the general Merkle tree logic. Specifically, on the original hash function, and wrapped with a layer, makes the node hash into shape, such as "minNs | maxNs | original hash", in the form of minNs and maxNs were all child nodes of this node, the minimum and maximum namespace. It is easy to see that the leaf node has minNs = maxNs because it contains only one message and can have only one namespace. Merkle tree is a binary tree, and we have sorted the messages, so for non-leaf nodes minNs equals the minNs of the left child and maxNs equals the maxNs of the right child. Also, note that the original hash function takes the entire hash of the child node as input, meaning that the namespace is also involved in the hash calculation, so you cannot write arbitrarily, otherwise the root hash will be inconsistent with the record in the block, and it is easy to see that the data is invalid. Below is a diagram of a Merkle tree with namespaces (nodes have been numbered in hierarchically priority mode R1, H2... H15) :
Prove message integrity:
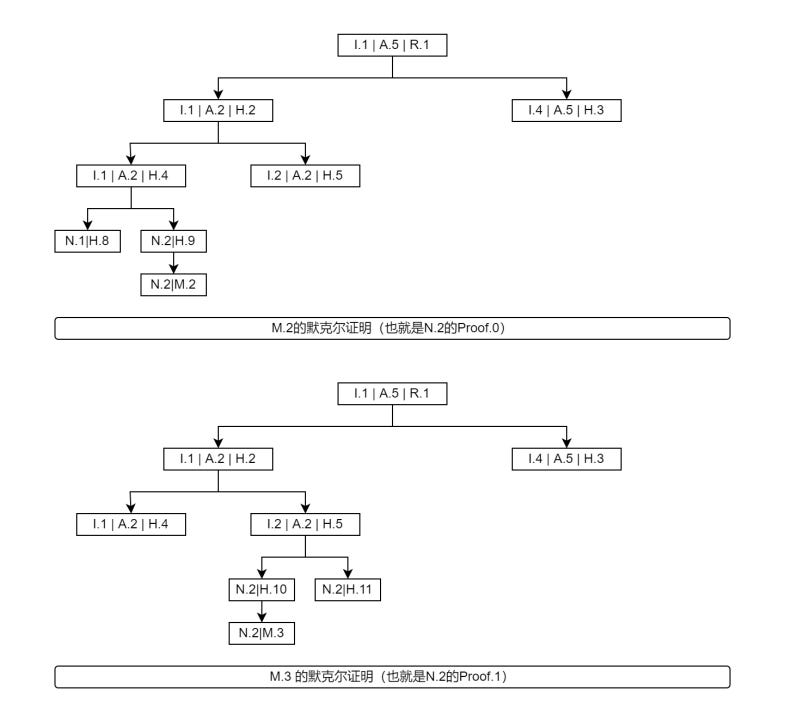
First, you need to prove that some message returned is actually in the message tree, and that's what the ordinary Merkle inclusion proof does. Therefore, when the storage node returns a message, it also returns the Merkle inclusion proof of the message. Given the return message M0 to Mn, that would also return the corresponding Merkel-containing proofs P0 to Pn. We need to explain that the storage node can not return a message, but cannot change the Merkle tree of the message, because that would cause the root hash to change and the data to become invalid.
Now let's look at leaks. First of all, our messages are grouped together by namespace, so if a namespace leaks messages in the middle of all its messages, then any Merkle proof will show that the messages are not continuous, so there's no further discussion.
Let's look at the beginning or the end of the leak, and they're similar, so let's take the beginning. For example, if the first message m.2 of N.2 is missing, its corresponding p.0 will not be sent, so that, from the inquirer's point of view, the original P.1 (i.e., the Merkle proof of M.3) is now the first proof, and it checks the first proof anyway. In the following figure, I draw the details of P.0 and P.1. When we compare the differences between them, we find that the nodes on the left of M.2 have A namespace smaller than that of M.2, while the nodes on the left of M.3 have A node H.4 whose maxNs is A.2 equal to that of M.3. The source of this A.2 is the hidden M.2 of the storage node (see the figure of p.0). In this case, the execution node detects the exception.
What if all messages in a namespace are hidden? We stipulate that when a message for the specified namespace does not exist, we return a Merkle proof for a leaf node that has minNs greater than the target namespace but maxNs smaller than the target namespace for all nodes to its left (as shown above, if we assume that N.2 is empty, Merkle proof of M.5 should then be returned). So, when a storage node hides the entire namespace, of course, depending on the location of the node to be returned (e.g., if it returns M.5, it actually misses the message at the beginning. It may return a Merkle proof of M.8), either a node with maxNs greater than or equal to the target namespace to the left (H.14), or (for example, a Merkle proof returning M.1) a node with minNs less than or equal to the target namespace to the right (H.9). This allows the execution node to find the problem. In summary, storage nodes cannot hide messages undetected.
Conclusion:
This article retells part of the Celestia white paper on countering malicious storage nodes in multiple application scenarios such as sharding or side chains. The Celestia test network is now live, but more recently it has demonstrated support for light nodes and the feasibility of grouping messages. In the white paper, chapter 3 and Chapter 4 both mention more content about application sovereignty or sharding, which are partial concepts. For the real public network environment, the specific implementation is not clear at present. And the expansion problem is obviously the most concerned target in the whole blockchain field in the near future. So we'll be watching Celestia's progress in supporting standalone applications in particular, and it will be interesting to see how it can be combined with L2 or other "blockchain modules" to achieve practical functionality and increase on-chain capacity.
The original neighbors
Welcome to join the official BlockBeats community:
Telegram Subscription Group: https://t.me/theblockbeats
Telegram Discussion Group: https://t.me/BlockBeats_App
Official Twitter Account: https://twitter.com/BlockBeatsAsia