

 Forum
Forum Finance
Finance
 Specials
Specials
 On-chain Eco
On-chain Eco
 Entry
Entry
 Podcasts
Podcasts
 Activities
Activities
 OPRR
OPRR

Understand the role of ZK in AI on the propulsion chain

原文标题:《 一文了解 ZK 在推进链上 AI 的作用 》
Modulus Labs
The DeFi way
It's a pleasure to finally share with you our first paper, which was done through a grant from The Ethereum Foundation, titled The Cost of Intelligence: Proving the Machine Learning Inference with Zero - Knowledge "(or paper0, this is cool kids call it).
Yes, these are real numbers! There are charts! The theoretical structure and its effect on performance are also discussed! In fact, paper0 is the first research effort to benchmark ZK proof systems across the general AI primitive suite, and you can read the entire paper right now.
And this article, you can think of it as a summary of the paper, see the original paper for details.
Without further ado, let's dive into:
Paper0: Key points of our investigation
In fact, the future of computing will use a lot of complex artificial intelligence. Take a look at my text editor:

Notion's hint told me that their LLM could make this sentence even better
However, there is no functional neural network on the chain, not even a minimal recommendation system or matching algorithm. What the devil! Not even an experiment... The reason, of course, is very obvious, because this is too expensive, after all, even running calculations worth hundreds of thousands of Flops (just enough to reason once on a miniature neural network) costs millions of gas, currently equivalent to hundreds of dollars.
So, if we want to take the AI paradigm into a trust-free world, what should we do? Do we roll over and give up? Of course not... Wait! Roll-over)... Give The up...
If Rollup services like Starkware, Matter Labs, and others are using zero-knowledge proof to massively scale computing while keeping cryptography secure, can we do the same for AI?
This question became the motivating seed that drove our work in paper0. Revealing plot alert, here's what we found:

"Modern ZKS are proving that systems are increasingly capable and diverse, and that they can support AI operations at a reasonable cost to some extent.
In fact, some systems are much better at proving neural networks than others.
However, all of this still falls short of the performance required for real-world applications and is woefully inadequate for magic use cases.
In other words, without further acceleration of ZK systems for AI operations, there will be very limited use cases."
paper0 Summary
It's a well-known secret: AI performance is almost always proportional to model size. And the trend doesn't seem to be slowing down. As long as this remains the case, it will be particularly painful for those of us in web3.
After all, counting costs is the ultimate, inevitable source of our nightmares.

Today's ZKP already supports small models, but medium to large models break the paradigm
Benchmark: Experimental design
For paper0, we focus on 2 basic indicators in any zero-knowledge proof system:
- Proof generation time: the time required for prover to create the adjoint proof of AI inference, and
- prover memory usage peak: the maximum memory used by the prover to generate the inference proof at any given time during the proof;
This was primarily a practical choice, and was made from our experience building the Rockybot (demonstrating that time and memory usage are immediate priorities in determining the feasibility of any use case without trusting AI). In addition, all measurements were made for proof generation time, and no preprocessing or witness generation was considered.
Of course, there are other costs to keep track of. This includes the verifier run time and proof size. We may revisit these metrics in the future, but consider them to be outside the scope of paper0.
As for the actual proof systems we tested, we selected six by vote:
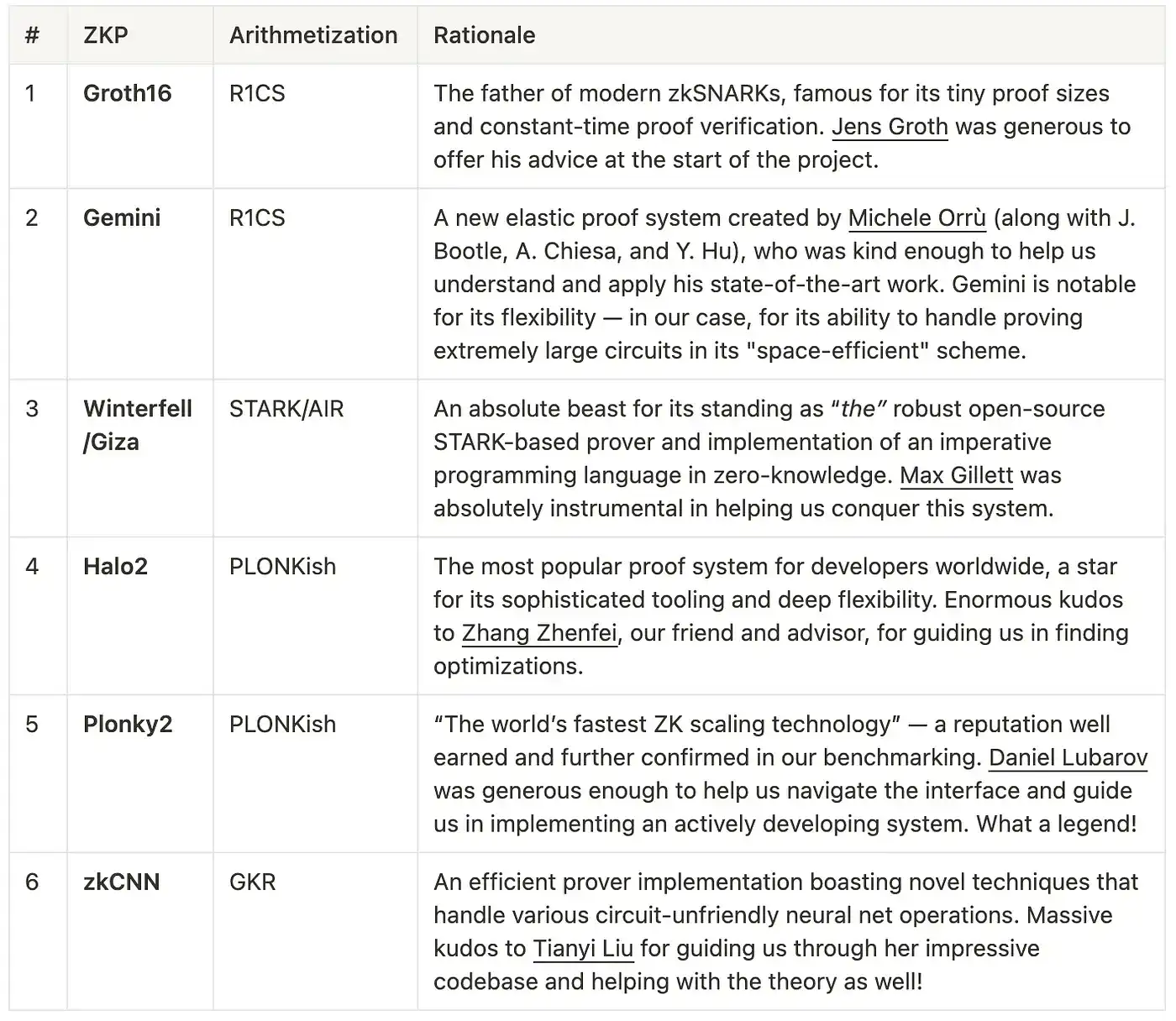
Summary table of proof system for Paper0 tests, as well as assisting our authors
Finally, we created two sets of multilinear perceptrons (MLPS) for benchmarking -- notably, MLPS are relatively simple and consist mainly of linear operations. This includes a set of architectures that scale as the number of parameters increases (up to 18 million parameters and 22 GFLOP), and a second set that scales as the number of layers increases (up to 500). As shown in the table below, each suite tested the ability to prove that the system scales in different ways and roughly represents the scale of well-known deep learning (ML) architectures from LeNet5 (60,000 parameters, 0.5 MFLOP) to ResNet-34 (22 million parameters, 3.77 GFLOP).
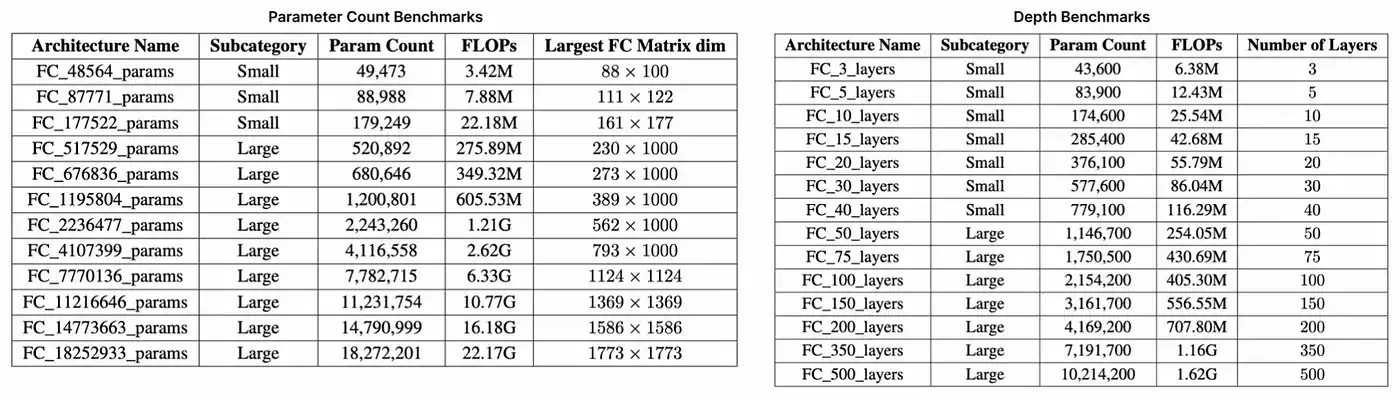
Parameter and depth reference suite
The result: Lightning fast
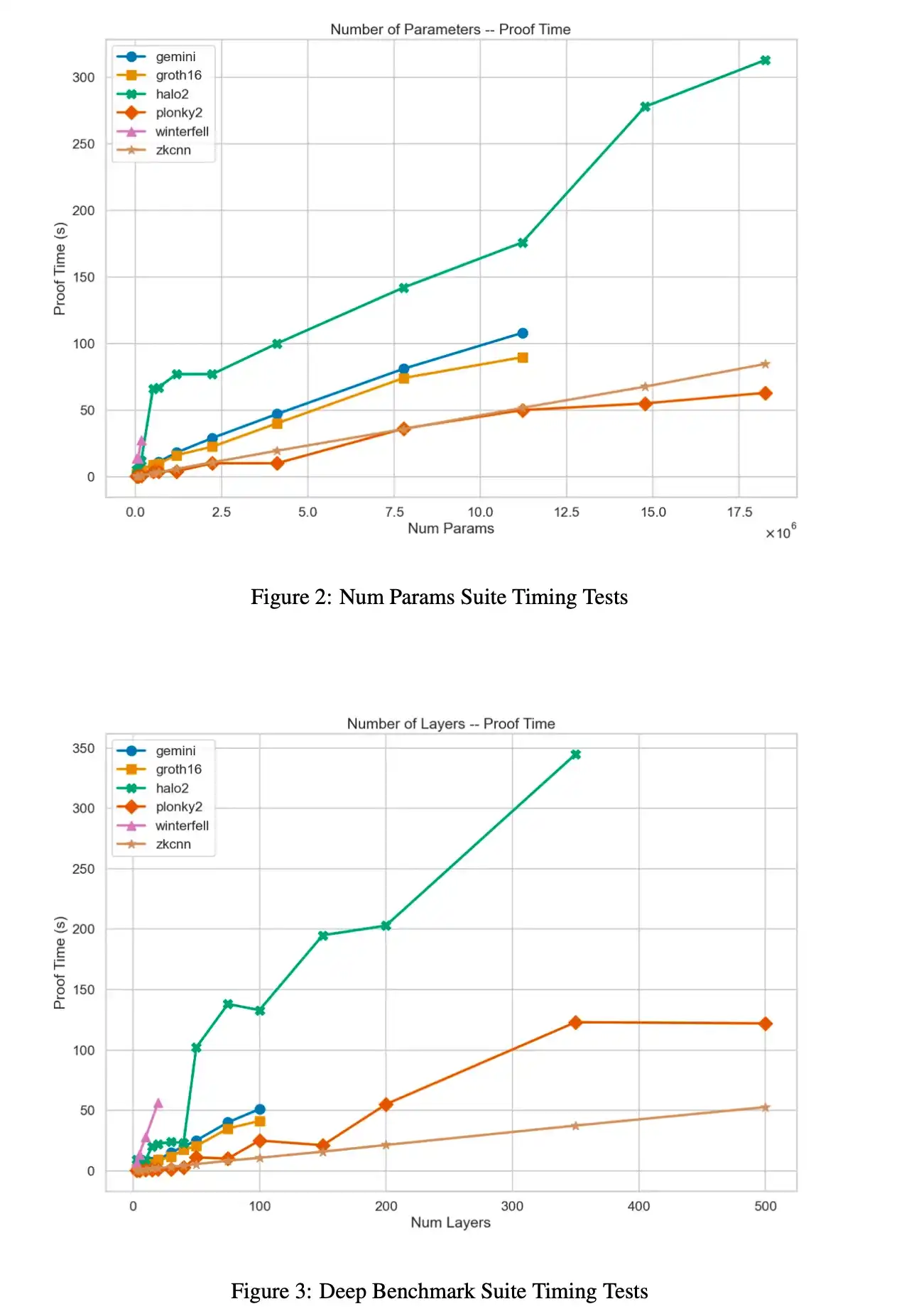
Time results are generated for the parameters and depth ranges of the above 6 proof systems

For the above 6 proof system parameters and depth range of peak memory results
For a complete breakdown of these results, as well as an in-depth analysis of bottlenecks within each system, see section 4 of paper0.
Use cases and final points
Well, those are some pretty neat graphs, and here are the main points:
"Plonky2 is by far the best performing system in terms of proof time because of its use of the FrI-based polynomial commitment and the Goldilocks domain. In fact, for our largest benchmark architecture, it is 3 times faster than Halo2.
However, this comes at a significant cost to prover memory consumption, with Plonky2's consistently poor performance sometimes doubling Halo2's peak RAM usage.
In terms of proving time and memory, the GKR-based zkCNN prover seems best suited to handle large models - even without optimized implementations."
So what exactly does this mean in practice? We'll focus on two examples:
1. Worldcoin: Worldcoin is building the world's first "privacy-protected identity protocol" (or PPPoPP), in other words, solving the witch attack problem by linking authentication to a very unique biometric signature (iris). It's a crazy idea that uses convolutional neural networks to compress, transform, and prove stored iris data. While their current setup involves a trusted computing environment within a secure enclave in orb hardware, they want to use ZKP instead to prove the model computes correctly. This would allow users to self-protect their biometric data and provide encryption security (as long as it is processed on the user's hardware, such as a mobile phone).
Now to be specific: Worldcoin's model has 1.8 million parameters and 50 layers. This is the model complexity necessary to distinguish between 10 billion different irises. Ouch!
While proving systems such as Plonky2 on computationally optimized cloud cpus can generate inference proofs for models of this scale in minutes, the memory consumption of the prover will exceed that of any commercial mobile hardware (tens of gigabytes of RAM).
In fact, no test system has been able to prove this neural network on mobile hardware...
2. AI Arena: AI Arena is an on-chain platformer fighting game in the style of Smash Bros. with a unique feature: Instead of playing avatars against each other in real time, players have player-owned AI models compete and fight each other, and yes, that sounds cool.
Over time, the amazing team at AI Arena is working hard to shift their game to a tournament plan that requires no trust at all. The problem, though, is that this involves the challenge of verifying the staggering amount of AI calculations per game.
The game runs at 60 frames per second for three minutes. This means that there are more than 20,000 inferences between the two player models per round. Taking a strategy network at AI Arena as an example, a relatively small MLP takes about 0.008 seconds to perform a forward pass, and proving the model using zkCNN takes 0.6 seconds, i.e., 1000 times more computation is required for each action taken.
It would also mean a 1,000-fold increase in computing costs. As unit economies become more important to on-chain services, developers must balance the value of decentralized security with the actual cost of proof generation.

https://aws.amazon.com/ec2/pricing/
Whether it's the examples above, ZK-KYC, DALL-E style image generation, or large language models in smart contracts, there is a whole world of use cases in the world of ZKML. However, to really make this happen, we strongly believe that ZK prover still needs a lot of improvement. Especially for the future of the self-improving blockchain.
So where do we go from here?
We have concrete performance data, and we know which technologies tend to perform best in proving neural networks. Of course, we started to find use cases that inspired our growing community.

I wonder what happens next...
More updates for you soon;)
Original link
Welcome to join the official BlockBeats community:
Telegram Subscription Group: https://t.me/theblockbeats
Telegram Discussion Group: https://t.me/BlockBeats_App
Official Twitter Account: https://twitter.com/BlockBeatsAsia






