

 Forum
Forum Finance
Finance
 Specials
Specials
 On-chain Eco
On-chain Eco
 Entry
Entry
 Podcasts
Podcasts
 Activities
Activities
 OPRR
OPRR

Cysic: How does zkVM become a new paradigm for the ZK industry?
Original title: 《New Paradigm in Designing ZK-ASICs, the zkVM way》
Original author: Cysic team
Thanks to Justin Drake and Luke Pearson for the insightful discussion.
TL;DR
Real-time zero-knowledge proof generation requires end-to-end hardware acceleration. zkVM not only simplifies the design of ZK ASICs, but also makes the hardware more performant and less expensive.
Introduction
Zero-knowledge proofs (ZKPs) allow one party (the prover) to prove to another party (the verifier) that a statement is true, without revealing any information other than the validity of the statement itself.
Silvio Micali, one of the inventors of zero-knowledge proofs (co-invented with Goldwasser and Rackoff), once said that just as encryption obfuscates data, zero-knowledge proofs obfuscate computations. More specifically, encryption algorithms (such as AES or RSA) can transform data into corresponding ciphertexts, which hide the underlying data. Zero-knowledge proofs transform computational statements into proofs that not only hide the details of the computation, but also verify the correctness of the statement.
ZKP has two good properties - zero knowledge and simplicity. This also makes it one of the most widely used high-level cryptographic primitives.
Zero-knowledge means that the proof itself does not reveal any information about the computation process and private inputs. This feature is very useful for building some privacy-oriented applications. For example, Aleo, unlike Bitcoin, Ethereum and other public chains, can hide transaction details.
Simplicity refers to the small size of the proof and the short verification time, which means that the complex computation process can be converted into a small piece of data (i.e., "proof"). And it can be verified almost instantly on weak computing devices (such as mobile phones or even Raspberry Pi). This feature is extremely useful when scaling Ethereum. We can convert the EVM calculation corresponding to 1,000 transactions into a tiny proof and then publish this proof on Ethereum. If such a small proof (maybe only 100 bytes) is verified by Ethereum, then the entire 1,000 transactions can be finalized. Private blockchains and scaling solutions are just two examples of the ZKP craze in the blockchain community. Many ZK projects can also be built using these two key properties, such as ZK coprocessors, ZK bridges, and ZK machine learning (ZKML).
The Current State of ZK Hardware Acceleration
A significant barrier to widespread deployment of ZKPs is the huge computational time and resource requirements of the proof generation process.
Generally, more complex computations require more time and resources. For example, in the ZKML project by Daniel Kang and his team, proof generation for GPT-2 inference takes over 9000 seconds using a powerful 64-thread CPU. On the other hand, proof generation for the ZK-EVM circuit in Scroll requires over 280GB of RAM.
Due to these prohibitive resource requirements, the community is seeking more efficient hardware that is tailored for ZK computations (referring to proof generation). Hardware options include CPUs, GPUs, FPGAs, and ASICs. These options range from being available now to having an indeterminate waiting period.
CPUs are often considered as a baseline implementation for comparison with the other three options. There are two common metrics for hardware acceleration, and here are some intuitive explanations:
· Performance per dollar: This means how much money users have to pay to buy this hardware. The purchase decision depends on many factors, the most important of which is the maximum performance that can be obtained with the same expenditure. Basically, this metric measures the cost-effectiveness of the hardware. Generally, if a more advanced process is used to manufacture the chip, we can get higher performance, but it is often more expensive.
· Performance per watt: This means how much energy is required to run this hardware. For example, Bitmain's latest Bitcoin miner T21 only uses 19 joules to complete 1 TH of calculations, outperforming its competitors' products.
The advantages of the product mainly depend on the above two factors, as well as some non-technical factors (such as warranty and residual value). Generally, due to the customized nature, ASIC-based hardware exceeds the other three hardware in these two indicators.
Let’s imagine that a specialized ZK ASIC has been designed that outperforms existing GPUs and FPGAs in terms of performance per dollar and per watt. This ASIC can support a variety of modules, such as multi-scalar multiplication (MSM), number theoretic transforms (NTT), Merkle trees, etc., but how can we integrate this hardware with the current technology stack?
The most common approach is to replace the corresponding calculations in the CPU code with acceleration components. This simple replacement method usually does not achieve satisfactory performance acceleration. We published our findings on this approach at ethCC』23 (more details in this tweet).

CPU vs FPGA/CPU Performance
We have made substantial progress using a combination of CPU and our custom FPGA machine compared to CPU performance, but the performance is still far from the ultimate goal - real-time ZK proofs.
This suboptimal performance is due to Amdahl's law and the interaction costs between different hardware components. Amdahl's law states that the overall performance improvement obtained by optimizing a single part of the system is limited, and this is further exacerbated by the communication costs between different hardware modules (from Wikipedia). In order to achieve significant speedups relative to the CPU, every possible component needs to be accelerated on a single piece of hardware.
However, this seems impossible due to the diversity of ZK algorithms (to be clear, ZK algorithms refer to the computational operations in ZK proof generation). For example, the above Twitter screenshot shows three ZK circuits, Poseidon Hash, EVM, and GPT-2, where the computations are still very different, especially in the witness generation part, despite using the same proof backend (Halo2-KZG). The screenshot also does not include different proof backends (such as Plonky2/3 and Gnark).
The point we want to make here is that the hardware needs to be general enough to accommodate the various on-chip computational operations of ZK algorithms. This versatility can be achieved through a hybrid structure of FPGAs and ASICs, as we proposed in this tweet in 2022:
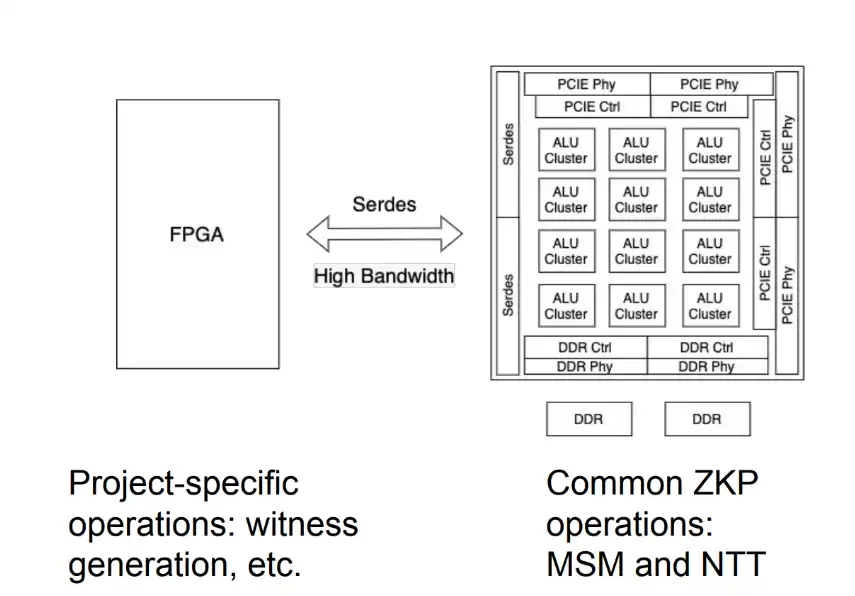
FGPA-ASIC Hybrid Architecture
In this hybrid structure, the ASIC performs common operations, while the FPGA performs circuit-specific calculations. The two hardware devices are then mounted on the same PCB board and connected via high-bandwidth SerDes channels. In addition, on-chip CPU cores such as RISC-V or ARM-based can also be used for similar purposes. These hybrid approaches usually have extremely high requirements in terms of cost and manufacturing quality. Over the past six months, we have been asking ourselves:
Is "hybrid" the best structure we can think of? Can we rely on the technical progress of the ZK community to improve our design? Below, we give positive answers to the above questions.
Cysic's solution, past and present
Before diving into the technical details, we first need to introduce some basic knowledge about zero-knowledge proof (ZKP). The typical proof generation process of the Plonkish proof system can be divided into the following stages (for a detailed analysis of proof generation, please read this blog by Scroll):
1. Record witness: Witness, also known as trace. It refers to some data that, together with other data, shows why a statement is true. Recording is done through a two-dimensional matrix called a trace table. Each entry in the table is an element of a finite field. The process of filling the trace table is called "witness generation", which requires traversing each cell in the table and filling in the correct value. This process requires arithmetic operations on finite fields and is customized for specific ZK circuits.
2. Submit witness: After witness generation, we get a trace table, each column of which is interpreted as a polynomial through Lagrange interpolation. These polynomials can then be committed using different commitment mechanisms, such as KZG and FRI. The main computations involved here include polynomial multiplication (MSM), number theoretic transformations ((I)NTT), polynomial flattening, and Merkle trees. Due to the complex computations on large finite fields and the huge amount of data required, this becomes a bottleneck for proof generation.
3. Prove that the witness is true: Now the trace table is filled in and the commitment has been calculated. The only thing left to do is to show that the trace is valid. This means that certain specific constraints are satisfied. The computations involved include number theoretic transformations ((I)NTT), polynomial multiplication (MSM), and polynomial flattening.
In summary, the computations in proof generation include several common modules: such as polynomial multiplication (MSM), number theoretic transformation (NTT), Merkle trees and polynomial flattening, as well as some additional modules.
In our previous blog, we showed some high-level strategies for optimizing these common modules. In the past few years, the community has also proposed some promising techniques to accelerate these common modules (see the works of Ulvetanna, Ingonyama and other teams). We will not repeat these techniques here.
These modules are no longer bottlenecks in terms of performance, but the end-to-end proof acceleration is far from satisfactory. This semi-finished accelerator can be seen as a dedicated GPU version with some performance improvements. A rough comparison is as follows:
· Advantages: In addition to the traditional GPU-style SIMD/SIMT parallel computing model, ZK computing is also specifically supported. This allows us to implement ZK operations with full performance without relying on cutting-edge CUDA programming skills (such as writing large integer operations with CUDA).
· Disadvantages: Programming complexity
· For accelerators, we provide a high-level programming model similar to the PyTorch style in AI, with the goal of providing a coding experience that is "as if translated directly from the paper" when part of the prover is placed on the accelerator. Although we provide flexible scheduling and control capabilities at the hardware level, this still requires understanding the underlying hardware design.
· For GPU users using CUDA, they have relatively complete control freedom when using it directly. They can make arbitrary optimizations. But this also means that they have to start everything from scratch.
Obviously, this semi-finished accelerator does not achieve the best end-to-end proof acceleration or user-friendly programming interface. We obviously need to add some new elements to our solution.
This new element is zkVM!
What is zkVM?
Virtual machines (VMs) are an old topic in computer science, which is basically a program that can run other programs. For example, the Ethereum Virtual Machine (EVM) can run Ethereum smart contracts, and the instructions it supports are specified in this yellow paper. As we know, zero-knowledge proof systems involve circuits, so zkVM is a circuit that can run a sequence of supported instructions. In addition to the execution result, zkVM also outputs a proof showing that the VM execution trace corresponding to the instruction sequence is valid.
In short, a zkVM is a ZK circuit that runs a VM (summarized from David Wong’s article).
There are two parts worth considering in zkVM design:
· Supported instruction sets: This means the operations that the VM can perform. There are several existing players in this space, such as Risc0, Succinct, Starknet, Polygon, Metis, etc., who work on different instruction sets, such as RISC-V, MIPS, or custom instruction sets.
· ZK architecture: This part involves the ZK proofs generated along with the execution results. The ZK architecture is mostly agnostic to the underlying VM design, but there are still some subtle balancing acts to consider.
A nice feature in the zkVM design is called continuations (from RISC0). In zkVM execution, continuations are a mechanism for splitting large programs into several pieces that can be independently computed and proved, as shown in the following figure:
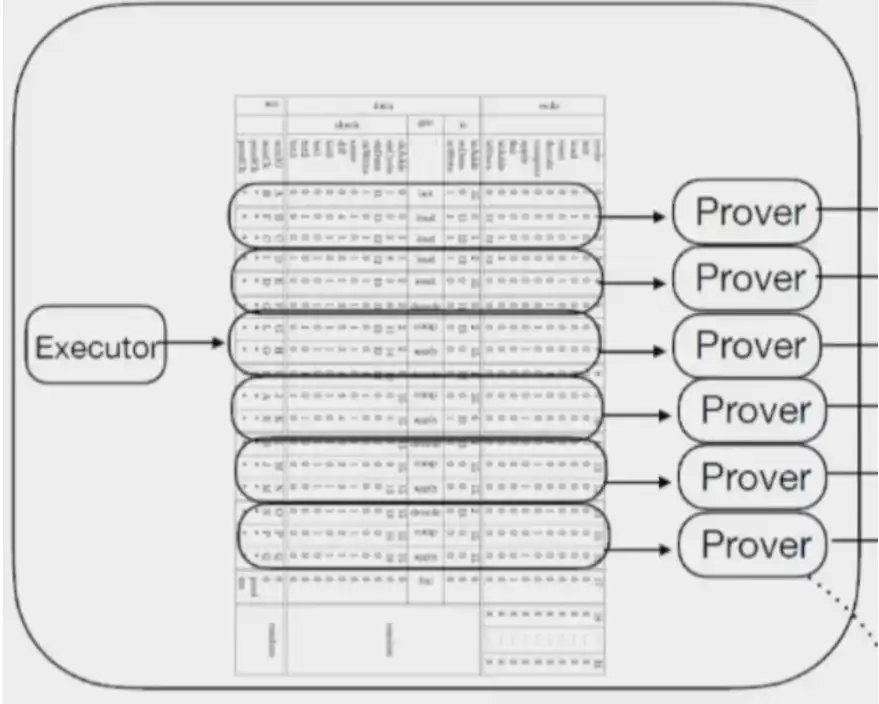
Segmented Process (Source: Risc0)
This feature is hardware-friendly for the following reasons:
Parallelism: Since these pieces do not depend on each other, they can be distributed to multiple hardware to generate corresponding proofs simultaneously.
· Minimize I/O bandwidth requirements: zkVM's proof generation follows a "small in, small out" model. For example, in Risc0, the fragment size of the proof generation is about 50MB, and the output is a FRI-based proof with a size of about 250KB. This special model greatly reduces the I/O bandwidth requirements.
· Manageable memory requirements: Although the input and output of each proof generation core are small, the memory requirements are large, ranging in the tens of GB. However, the size of the required memory depends on the size of the fragment, which can be adjusted according to the design of the zkVM.
Based on these hardware-friendly features, we describe our hardware design in the following.
Hardware Design Based on zkVM
The architecture of the system is relatively simple, with an executor responsible for executing the program, hardware responsible for controlling and distributing each "fragment (as described above)", and a configurable number of dedicated chips to generate ZK proofs for each part of the program.
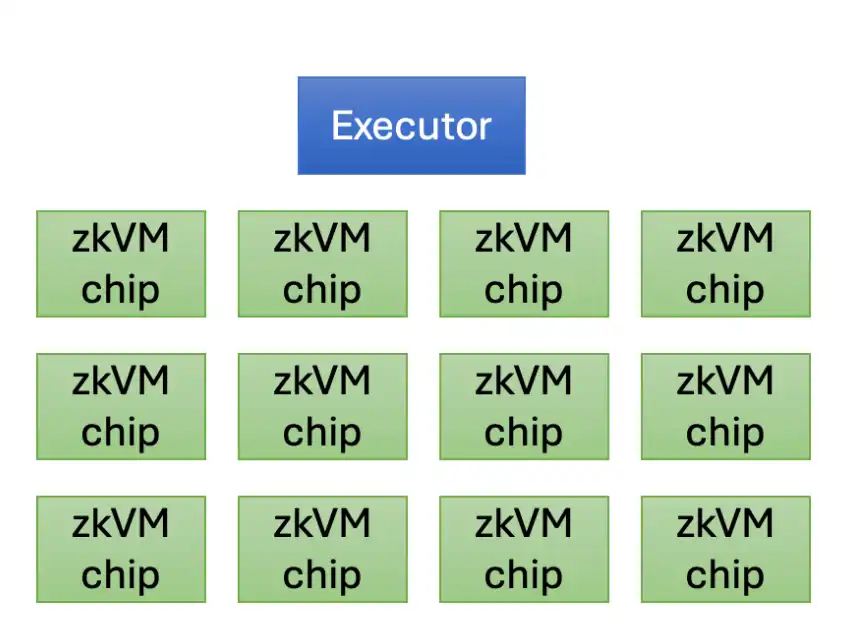
This simple architecture allows our hardware to have a flexible form factor. We can pack an executor (using a weak CPU or on-chip CPU cores), a number of zkVM chips, and other necessary hardware components (such as memory) into a single chassis. A simpler case would be to pack multiple chips into a portable machine, like a Macbook charger.
The zkVM hardware includes several computational cores:
· A programmable vector machine for vectorized operations.
· Dedicated NTT modules for 31-bit, 64-bit, and 256-bit fields.
· Dedicated MSM modules supporting BN254, BLS12–377, and BLS12–388 curves.
· Configurable hash function unit for hash functions based on field operations.
In addition to the advantages brought by zkVM, this new paradigm of designing ZK-ASICs has also translated into a multitude of great products for personal or enterprise use, as shown below:
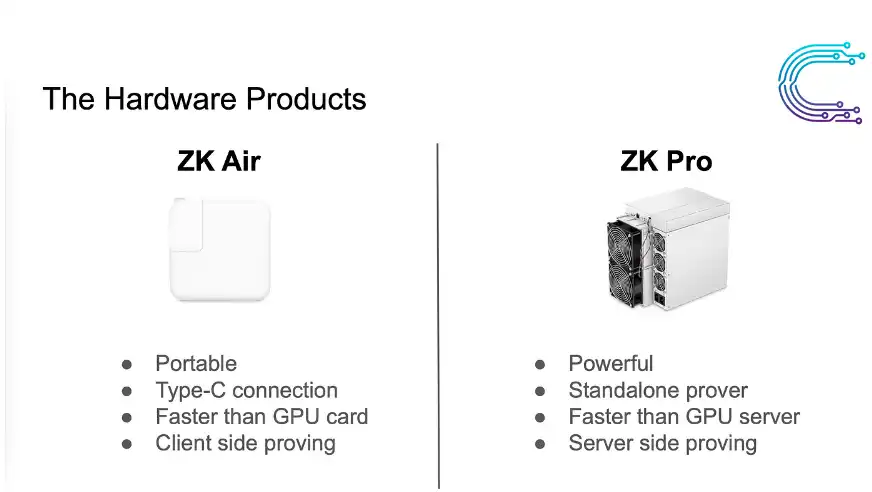
ZK ASIC Products
Collaboration is welcome
The zkVM hardware project Cysic aims to build cost-effective hardware for a wide range of use cases, performance, and development productivity. We seek diverse perspectives, innovative ideas, and committed input to improve and expand our hardware designs. We look forward to community participation and input, and are ready to provide guidance and support to anyone interested in participating.
This article is from a contribution and does not represent the views of BlockBeats.
Welcome to join the official BlockBeats community:
Telegram Subscription Group: https://t.me/theblockbeats
Telegram Discussion Group: https://t.me/BlockBeats_App
Official Twitter Account: https://twitter.com/BlockBeatsAsia







