Forum
Forum Finance
Finance
 Specials
Specials
 On-chain Eco
On-chain Eco
 Entry
Entry
 Podcasts
Podcasts
 Activities
Activities
 OPRR
OPRR

How Grass draws a data map of the entire network for the AI era
In order to get a ticket to the AI finals, the giants are spending a lot of money to buy high-quality data.
In the AI era, data, like computing power, is a necessity. Reddit once revealed in its IPO prospectus that it has achieved a total revenue of US$203 million through data licensing agreements signed with AI companies. Previously, Information reported that OpenAI is offering publishers an annual offer of US$1 million to US$5 million to get more news organizations to sign licensing agreements to train its AI models.
As for the protection of high-quality data, the most obvious example is X (formerly Twitter)'s strict restrictions on APIs starting in 2023. Musk, who once invested in OpenAI, is very likely to have strictly restricted API access to X data because he knew that X was a data vault. To give the simplest example, although many people are used to using AI star product Perplexity instead of Google for search, only on the newly released Grok can users retrieve the latest posts on X. To some extent, it can be said that X's data has become Grok's biggest moat.

Grok can obtain and quote real-time data on X, which other search engines cannot do
Because of NVIDIA's existence, in the crypto circle, it seems that people only care about GPU projects, but few people realize that data is also a key resource for the development of AI. No matter how strong the computing power is, it cannot create miracles, and a good cook cannot cook without rice. Without sufficient data and high-quality data, the system cannot accurately understand, predict and generate content, and thus cannot operate effectively in the complex real world.
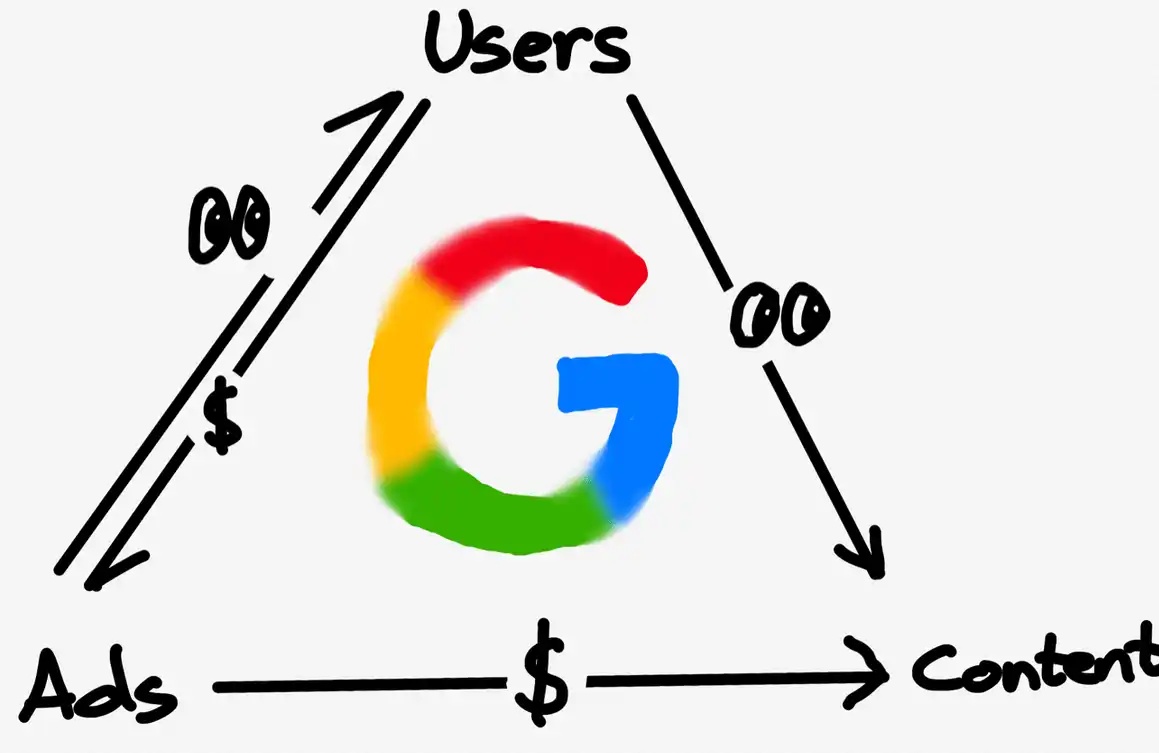
If the AI applications represented by Chatgpt and the AI computing power represented by NVIDIA are called the face, then giants such as Google and Microsoft integrate a huge part of the content of the entire network and provide the inside of AI.
Data is not only the foundation of AI, but also the moat of AI. In this regard, Grass, which is deeply engaged in the data layer, has already had a complete solution.
Why can Grass become a decentralized Google?
If I were to summarize Grass's core working philosophy in one sentence, it would be to come from the masses and go to the masses. Global users contribute idle bandwidth and relay traffic by running Grass nodes to capture real-time high-quality data from the entire Internet and obtain Token rewards.

Unlike traditional giants, Grass, as a leading encryption protocol for building projects in the data field, captures massive amounts of Internet data that are verified, sorted and cleaned to become high-quality data sets for sale. Any company or individual who intends to train their own AI can benefit from this system.
As Hack VC managing partner Ed Roman comment on Grass, this data acquisition will likely outperform any one company’s in-house data acquisition efforts due to the power of a large network of incentivized nodes. This includes not only acquiring more data, but also acquiring data more frequently so that it is more relevant and up-to-date. It is nearly impossible to stop a decentralized army of data scrapers because they are fragmented in nature and do not reside within a single IP address.
Of course, users will naturally care about security issues as they contribute their idle bandwidth. Grass also gave an explanation for this: When contributing excess bandwidth for data crawling, Grass will not use the user's computer or view any actions performed by the user on the computer. All it does is route Internet traffic through the user's IP address, which is completely unrelated to the user's activities, which means it cannot access the user's personal data.
Grass's extremely low entry threshold has accumulated a huge user base for it. Less than a year after its launch, Grass already has more than 2 million active nodes, and now has more than 2.2 million active nodes. If the points of these more than 2 million node users are converted into corresponding tokens after the Grass TGE, this may make Grass one of the most widely distributed airdrop projects and communities in history.

As one of the few products with good product-market fit (PMF), the Grass team not only demonstrated a strong technical foundation through stable operations, but also submitted a satisfactory answer to the market with technology and community cooperation. In July, the Grass Foundation released the UpvoteWeb dataset on Hugging Face, which contains 600 million top posts and comments on Reddit in 2024. It is the largest and latest open source Reddit dataset to date.
Reddit data is very valuable for AI models because it is manually labeled through the upvote mechanism, which ranks the quality of responses and classifies sub-forums where experts express their opinions. Google once reached an agreement with Reddit worth about $60 million to obtain data on Reddit for training its AI models.

UpvoteWeb was recommended by Caleb from Hugging Face
Grass's long-term goal is not limited to historical data. They intend to build a real-time contextual retrieval (LCR) engine that will utilize all Grass nodes to continuously crawl the Internet in parallel and around the clock, essentially turning Grass into a user-owned search engine like Google. In theory, any application or large language model (LLM) that wants to retrieve real-time data can use LCR.
In order to ensure the validity of the data used to train the model, Grass also introduced a ZK processor and a data ledger with timestamp-like functions. The ZK processor ensures that the AI model is trained correctly, and the metadata retained by the data ledger ensures the authenticity and source of the crawled data.
In addition to the existing achievements, Grass will continue to upgrade from both the chain and the node in the future to enhance data transmission and quality and improve network effects.
Eric Schmidt, who served as Google CEO for 10 years, said in his 2024 speech at the School of Computer Science at Stanford University that he once thought that NVIDIA's CUDA was not a sophisticated programming language, but now CUDA is NVIDIA's greatest moat, and all large models must run on CUDA. It also makes NVIDIA a well-deserved infrastructure and industry standard in the AI industry.
Grass, which has a large number of users, is working hard to become an AI data layer, which means that Grass can provide support for more AI application scenarios, from natural language processing to image recognition, to complex machine learning tasks, Grass's data layer can meet a variety of different needs, and eventually become an industry infrastructure like NVIDIA.

As an ordinary user, I was very puzzled when I first came into contact with the AI data layer, and I didn't know why it was necessary. With this curiosity, I carefully studied the design concept of Grass.
Because the Grass network has to process and store massive amounts of data, especially real-time data, this scale of data processing requirements far exceeds the limitations of traditional on-chain processing capabilities. If all data is processed directly on the main chain, even a network with a high TPS will face serious congestion problems, resulting in inefficiency.
Operating on the blockchain is usually accompanied by high costs. By processing and compressing a large amount of data off-chain, and then submitting the processed results to the main chain. This greatly reduces the data burden on the chain and improves the overall processing efficiency.
In addition, sensitive data also gains additional privacy protection through the ZK processor. Through the recording function of the original data, Grass may also incentivize high-quality nodes.
After solving the scalability, cost and privacy issues through the AI data layer. Grass also launched an application version of the node, which uses less than 5% of the resources of the Chromium browser, but processes 10 times more bandwidth than the Chrome extension.

Not only that, Grass will also launch a mobile version and a physical mining machine, which means that Android and IOS users can get rewards around the clock. Because the convenience of mobile phones is very likely to attract many Web2 users, greatly expanding the Grass network. And because the IP addresses of computers and mobile phones are different, old users can also get an additional income from the mobile phone.
High-quality background plus high PMF, amazing potential
Not only is the team technology continuously online and the community continues to pursue it, Grass, which already has a very high PMF, has a strong background of investors behind it.
Grass' parent company Wynd Network previously received seed round financing from Polychain Capital and Tribe Capital. Not only that, Multicoin managing partner Kyle Samani, who has been in the spotlight for betting on Solana, participated in Wynd Network's Pre-seed round of financing.

It is worth noting that Hack VC also mentioned its investment in Grass in the article. It is not sure whether this means that Grass has a new round of financing that has not yet been disclosed.
Some community members expect that after the Grass TGE, when people realize that they can make a lot of money passively through Grass without any risk, those who missed Grass will flock to it. This means that after the release, the potential and implicit demand coupled with the launch of the mobile application will increase the number of users dramatically. Depending on growth rates, attractiveness factors, and network effects, Grass could have 50 million users within a year.
As the crypto industry continues to disenchant new terms, revenue has become the focus of attention. According to House of Chimera, in the past three months, various DePIN projects have accumulated $500,000 each, and Akash has received $200,000.

The old problem of obtaining real income does not seem to pose any challenge to Grass. Take the Reddit dataset UpvoteWeb mentioned above as an example. For a similar dataset, Google needs to pay 60 million to obtain it.
Compared with Bright Data, a leader in data crawling and proxy services in the Web2 track. Whether it is $0.001 per record from Data for AI or $15,000 for 5 million requests from Perplexity, the 600 million Reddit dataset obtained by Grass is worth a lot of money.

Not to mention Reddit's own new policy of setting API fees at $0.24 per 1,000 calls starting in July 2023. You should know that the above data is only when Grass has not launched tokens, mobile versions and dedicated mining machines. Once Grass forms a stronger network effect, all data will be updated again.
Time is very important for systems with network effects. Grass has established a sufficiently broad user base and technical accumulation in the fields of encryption and even AI. I hope its flywheel can develop further and become a real AI data layer.

Just like the beautiful vision conveyed by the TOUCH GRASS challenge held by Grass for the community, Grass will become the data map of the AI era, transfer the benefits of centralized enterprises to more users, and give Grass community members more time to touch Grass.
Welcome to join the official BlockBeats community:
Telegram Subscription Group: https://t.me/theblockbeats
Telegram Discussion Group: https://t.me/BlockBeats_App
Official Twitter Account: https://twitter.com/BlockBeatsAsia