

 融资信息
融资信息
 专题
专题
 链上生态
链上生态
 词条
词条
 播客
播客
 活动
活动

三张图看英伟达GTC:算力越便宜,花得越多

黄仁勋昨晚在 GTC 2026 上发布了 Vera Rubin 平台,宣称单位功耗推理性能比 Blackwell 提升 10 倍,推理 Token 成本降到十分之一,并预告 Blackwell 与 Vera Rubin 的合并订单将在 2027 年前突破 1 万亿美元。
过去两年,GPT-4 同级别 API 的推理成本跌了 94%,从每百万 Token 36 美元降到不到 2 美元。按照直觉,算力变便宜了,企业应该少花钱才对。但 Amazon、Alphabet、Meta、Microsoft 四家云厂商的资本开支合计从 1540 亿美元涨到了 4160 亿美元,翻了将近 3 倍。
黄仁勋的万亿预告不是一句营销话术,它背后有一条可以用数据画出来的曲线。
每一代都让上一代显得可悲
从 2022 年的 H100 到 2026 年下半年即将量产的 Vera Rubin,英伟达 AI GPU 的 FP8 密集推理算力在四年间翻了 8 倍。据 NVIDIA 官方规格,H100 单卡 2.0 PetaFLOPS,B200 达到 4.0 PF,Vera Rubin 直接跳到 16 PF。
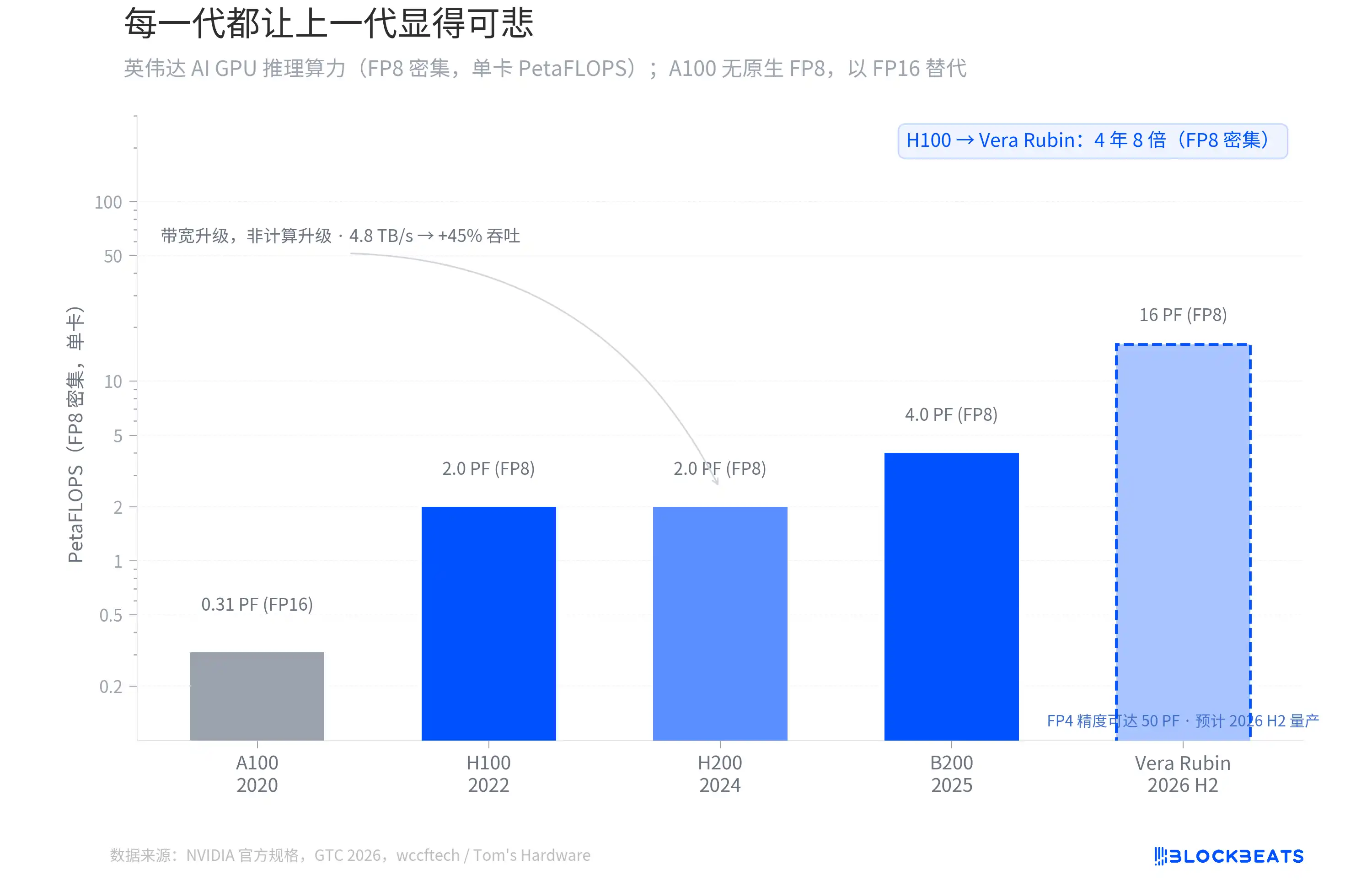
但不是每一代的跳跃都来自同一个地方。据 wccftech 报道,H200 的计算核心和 H100 完全一样,FP8 算力没有变化,它的升级全部来自内存带宽(从 3.35 TB/s 提升到 4.8 TB/s),带来约 45% 的推理吞吐提升。
真正的架构换代发生在 B200 和 Vera Rubin。Vera Rubin 采用台积电 3nm 制程,搭载 336B 晶体管的双 chiplet 设计,FP4 精度下推理算力达到 50 PF。据 Tom's Hardware 报道,第一台 Vera Rubin 系统已经在微软 Azure 上运行。
这里有一个容易被忽略的区分。黄仁勋在 GTC 上说的「10 倍」指的是推理 Token 成本的降低,不是原始算力的倍数。Token 成本包含了 Transformer Engine 优化、FP4 精度、更大批量推理等系统级因素。从标准化的 FP8 密集 TFLOPS 来看,Vera Rubin 相对 Blackwell 的倍数是 4 倍,相对 H100 是 8 倍。
这条曲线的斜率从未放缓。每一代 GPU 都让上一代显得不够用,而这正是接下来要讲的故事的起点。
Jevons 悖论:算力越便宜,花得越多
2023 年 3 月 GPT-4 刚上线时,API 调用成本是每百万 Token 约 36 美元。据 OpenAI 官方定价历史,到 2024 年中 GPT-4o 推出时降到约 7 美元,2025 年末实际可用价格已经低于 2 美元。两年间降幅超过 94%。
按照常理,推理成本跌了这么多,企业应该花得更少了。但现实完全相反。据各公司财报及 Platformonomics 追踪数据,Amazon、Alphabet、Meta、Microsoft 四家云厂商的年度资本开支合计从 2023 年的 1540 亿美元涨到 2025 年的 4160 亿美元,增幅 170%。其中 Google 单独从 320 亿涨到 915 亿(约 2.9 倍),Microsoft 的增幅更大。
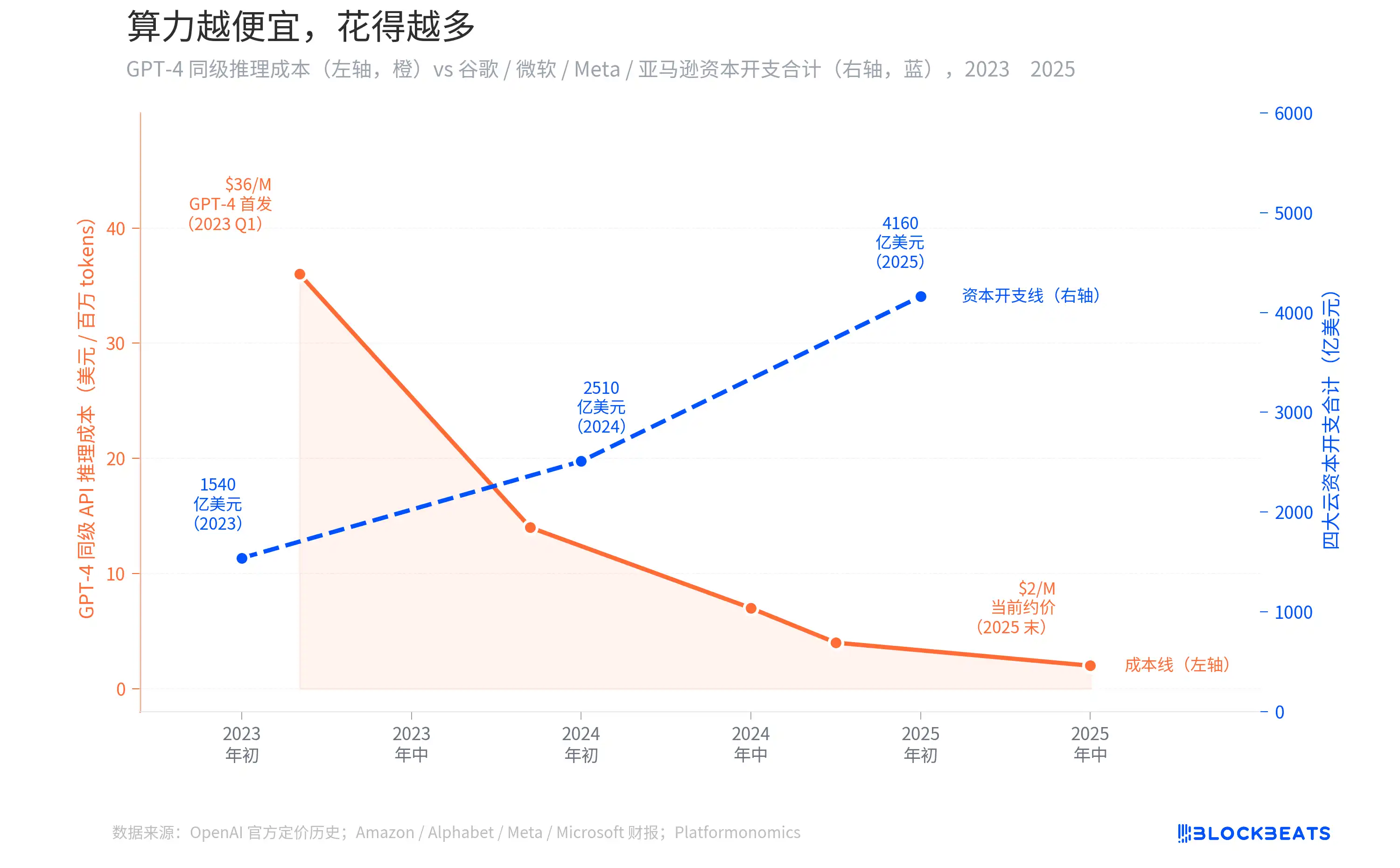
这个现象在经济学里有个名字,叫 Jevons 悖论。1865 年,英国经济学家 William Jevons 发现,瓦特改良蒸汽机让煤炭使用效率大幅提高,但英国的煤炭消耗量不降反升。原因很简单,效率提升让蒸汽机变得更划算,于是更多行业开始使用蒸汽机,总需求膨胀到远超效率节省的部分。
今天 AI 推理的情况一模一样。API 价格跌到原来的 6%,企业没有因此省下预算,而是开始把 AI 塞进之前成本上不划算的场景。客服、代码审查、内容生成、搜索重排序、广告出价,每一个新场景都在消耗更多的推理算力。需求的膨胀速度远远超过成本下降的速度。DeepSeek R1 在 2025 年初把输入价格压到每百万 Token 0.55 美元,进一步加速了这个循环。图上那两条反向运动的线,就是同一件事的两面。
三年 11 倍,且没有看到天花板
如果 Jevons 悖论有一个最直接的受益者,那就是卖铲子的人。
据 NVIDIA 财报,数据中心业务年收入从 FY2022(截至 2022 年 1 月)的 106 亿美元,涨到 FY2025(截至 2025 年 1 月)的 1152 亿美元。三个财年,10.9 倍。这条增速曲线在科技史上几乎没有先例。作为对比,iPhone 在 2007 年上市后,苹果用了大约 6 年时间才实现了类似量级的收入规模增幅。
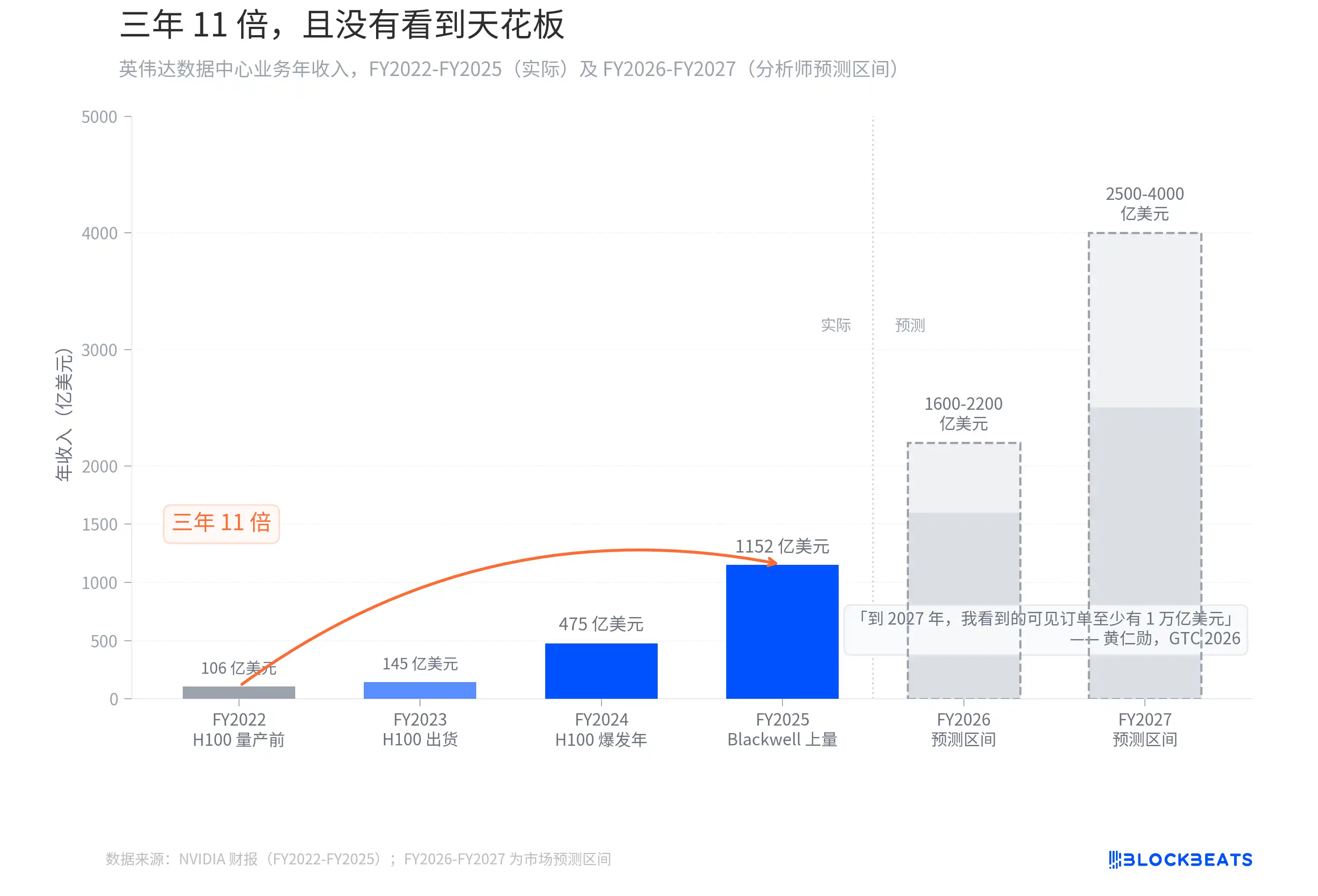
然后黄仁勋在 GTC 2026 上说:「到 2027 年,我看到的可见订单至少有 1 万亿美元。事实上,我们的产能会不够。我确信计算需求会远超这个数字。」
去年 GTC 他给出的预测是通过 2026 年可见订单约 5000 亿美元。一年之后,数字翻倍,时间窗口只延长了一年。分析师对 FY2026-FY2027 的营收预测区间分别在 1600-2200 亿和 2500-4000 亿美元之间。而黄仁勋自己说的是,这个数字不是天花板,「计算需求会远超这个数字」。GTC 结束当天,NVIDIA 股价上涨 4.3%。市场显然选择了相信他。
每一代 GPU 都让上一代显得可悲,每一轮降价都让下一轮资本开支显得理所当然。英伟达正站在这个悖论最甜蜜的位置上。
欢迎加入律动 BlockBeats 官方社群:
Telegram 订阅群:https://t.me/theblockbeats
Telegram 交流群:https://t.me/BlockBeats_App
Twitter 官方账号:https://twitter.com/BlockBeatsAsia
当单位算力成本急剧下降时,总需求并非线性收缩,而是呈指数级扩张。云厂商的资本开支在三年内增长170%就是明证。低成本推理使之前不经济的应用场景(如实时客服、广告出价优化、多模态生成)成为可能,从而催生更大的算力消耗。这类似于蒸汽机效率提升后煤炭总消耗量反而上升的历史规律。
英伟达的战略高明之处在于,它通过平台化绑定放大了这个悖论效应。从H100到Vera Rubin的演进路径显示,内存带宽、chiplet设计和制程升级在不同阶段成为性能突破点,但真正构筑壁垒的是软硬件协同生态。Dynamo操作系统对推理性能的7倍提升验证了这一点——硬件效率提升通过软件层被二次放大。
万亿订单预告的本质是算力需求曲线的斜率尚未见顶。当Token成本逼近边际极限时,应用场景的爆发式增长仍在持续。云厂商的巨额资本开支不仅流向训练集群,更密集投向推理基础设施,因为实时AI应用正在成为新的流量入口。
值得关注的是,英伟达通过Vera CPU切入Agent专属处理器市场,这标志着计算架构正从“以GPU为中心”转向“场景最优配置”。未来算力市场的竞争将不再是单纯的FLOPS竞赛,而是对特定工作负载的精细化匹配能力。
这种演化对加密行业的启示在于:去中心化算力网络需要构建类似的成本-需求正反馈循环。当验证者关注硬件投入回报率时,能否实现更低边际成本和更广应用场景将成为关键。目前中心化云厂商的规模效应仍在强化,但电力瓶颈和定制化需求可能为替代方案留下窗口。真正的突破点或许在于找到那些适合分布式算力架构的Agent应用场景,而非简单重复英伟达的路径。







 0
0