

 融资信息
融资信息
 专题
专题
 链上生态
链上生态
 词条
词条
 播客
播客
 活动
活动

美国AI初创要爱死中国开源模型了

美国花了三年、动用了四轮出口管制、涉及 24 类半导体设备和超过 140 个实体清单,试图切断中国获取先进 AI 芯片的通道。但据美中经济安全审查委员会(USCC)3 月 24 日发布的报告,80% 的美国 AI 创业公司正在使用中国开源模型。
墙建在硬件层。门开在软件层。
这组矛盾不是抽象的政策讨论。就在上周,估值 293 亿美元的 AI 编程工具 Cursor 被发现,其旗舰功能 Composer 2 的底层基座来自月之暗面的 Kimi K2.5。一家中国公司的模型,正在驱动美国最头部的 AI 开发工具。
与此同时,五角大楼把「供应链风险」的标签贴给了 Anthropic,一家美国公司。
管制的方向和实际依赖的方向,完全相反。
从 2022 年 10 月 BIS 首轮限制 A100/H100 级芯片出口开始,美国的芯片管制持续加码。2023 年堵上 H800 漏洞,扩大性能密度管制指标。2024 年 12 月再加一轮,新增 24 类半导体设备管制、将 140 个中国实体列入黑名单,连高带宽内存(HBM)和 DRAM 也被纳入限制范围。2025 年 1 月,商务部甚至推出了一个「AI 扩散框架」,试图从模型层面建立全球管制体系,但这个框架在正式生效前两天被自己撤销了。到 2025 年 12 月,特朗普又调转方向,允许 H200 芯片向中国批准客户出口。

在这条管制时间线的下半段,中国开源模型的发布节奏不断加速。2024 年,DeepSeek-V2 和 Qwen 2.5 系列相继开源。2025 年 1 月 20 日,DeepSeek-R1 和 Kimi K1.5 同日发布,前者一度登顶美国 App Store 下载榜,超越 ChatGPT。2025 年下半年 Kimi-K2 和 GLM-4.5 跟进。2026 年初,字节跳动的豆包 2.0 已拥有 1.55 亿周活用户,Kimi K2.5 则被 Cursor 直接采用。管制越紧,模型越多。
据 HuggingFace 官方数据,中国开源模型在全球下载中的占比从 2024 年底的约 1.2% 飙升至 2026 年初的约 30%。阿里 Qwen 系列的累计下载量在 2026 年 1 月突破 7 亿次,正式超越 Meta 的 Llama。芯片管制没有阻止中国 AI 的软件输出,反而可能加速了开源路线的战略转向。
这不是偶然的数据巧合。USCC 报告用了一个精确的框架来描述这个现象:「双循环」。硬件循环中,中国受制于芯片供应瓶颈。软件循环中,中国通过开源模型反向渗透全球 AI 基础设施,形成下游依赖。两个循环的力量方向相反,但互相强化。管制限制了我们获取顶级算力的能力,但也倒逼出一条用更少算力做更多事的技术路线。DeepSeek-R1 以远低于 GPT-4o 的推理成本达到前沿性能,就是这条路线的产物。
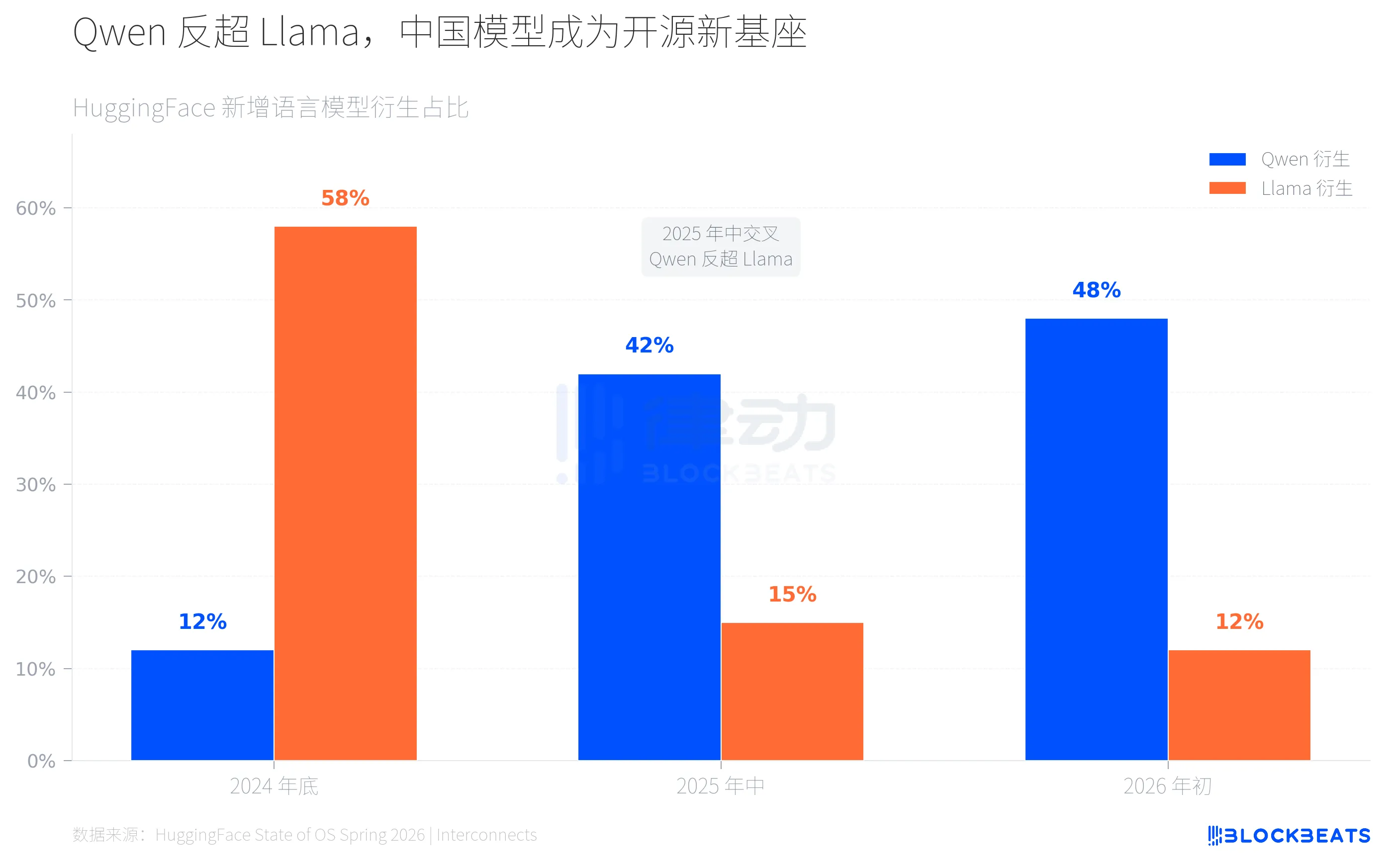
HuggingFace 上的变化肉眼可见。据平台统计数据,2024 年底 Llama 衍生模型占新增语言模型约六成,Qwen 仅占一成出头。到 2025 年年中,交叉点出现,据 HuggingFace 官方博客,Qwen 衍生占比飙升至 40% 以上,Llama 跌至约 15%。2026 年初,Qwen 衍生已接近半数,Llama 继续收缩至约 12%。
这个交叉的速度超出了大多数人的预期。两年前,开源 AI 几乎等同于 Meta 的 Llama 生态。全球开发者基于 Llama 做微调、做部署、做产品。现在,同样的事情正在 Qwen 生态上重演,只是速度更快、覆盖更广。
这意味着全球开发者在构建 AI 应用时,越来越多地选择中国模型作为底层基座。不是因为政治立场,而是因为性能和开放程度。Qwen 2.5 系列覆盖 0.5B 到 72B 参数量,开发者可以在自己的硬件上微调部署,不需要向 OpenAI 或 Anthropic 付费调用 API。开源消除了供应商锁定,也消除了国界。
一个值得注意的细节是,据 MIT Technology Review 2 月报道,中国 AI 公司在开源策略上正在形成差异化竞争。DeepSeek 走极致成本效率路线,Kimi 主攻长上下文和代码能力,Qwen 追求全参数量覆盖。这种多路线并进的态势,让全球开发者的选择越来越丰富。我们的开源模型正在用实力重新定义全球 AI 供应链。
但这条供应链的终端长什么样?
3 月 19 日,开发者 @fynnso 在 Cursor 代码中发现了模型 ID accounts/anysphere/models/kimi-k2p5-rl-0317-s515-fast。Cursor 联合创始人 Aman Sanger 随后承认 Composer 2 基于 Kimi K2.5 构建。据 Cursor VP Lee Robinson 的说法,「基座模型只贡献了约四分之一的计算量,其余来自我们自己的训练」。但底座就是底座。293 亿美元估值的产品,基座模型来自月之暗面,一家由阿里巴巴和红杉(HongShan)投资的中国公司。
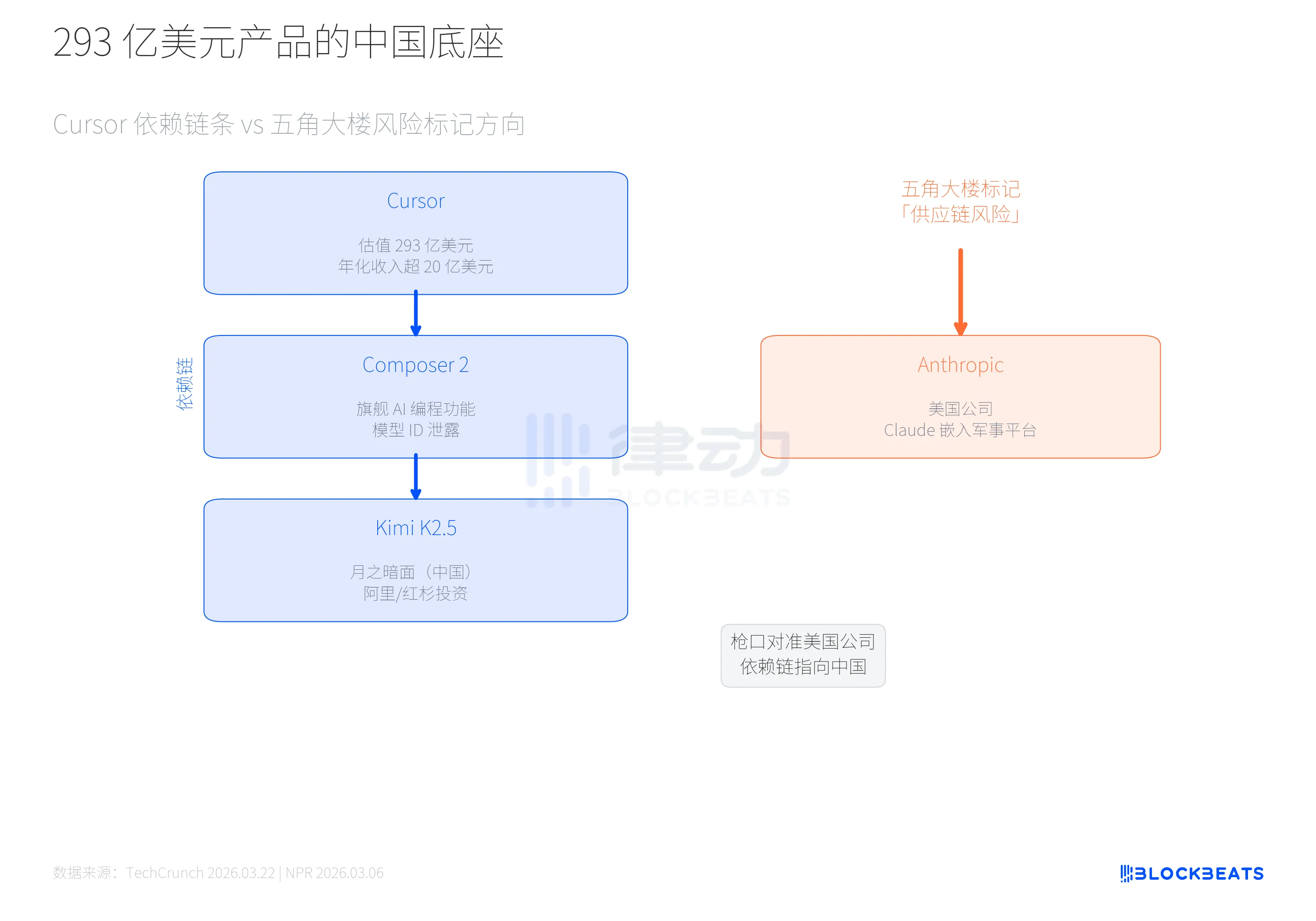
把这条依赖链和五角大楼的动作放在一起看,荒诞感更明显。3 月 5 日,五角大楼正式将 Anthropic 标记为「供应链风险」。据 NPR 报道,原因是 Anthropic CEO Dario Amodei 拒绝在两条红线上让步,即 AI 用于自主武器和大规模监控美国公民。特朗普给军方 6 个月时间淘汰 Claude,而 Claude 已深度嵌入军事和国家安全平台。Anthropic 随后在 3 月 9 日起诉五角大楼。
一边是美国政府把「供应链风险」标签贴给自家公司,另一边是 80% 的美国创业公司跑着中国模型。前者是政治博弈,后者是技术现实。两者之间没有交集。
80% 的美国创业公司跑着中国模型,五角大楼的风险标签贴在了一家美国公司身上。管制在硬件层层叠加,依赖在软件层悄然生长。三年芯片围墙的另一面,是一个正在成型的新事实:中国开源 AI 已经不是「追赶者」,而是全球 AI 基础设施的供给侧。
欢迎加入律动 BlockBeats 官方社群:
Telegram 订阅群:https://t.me/theblockbeats
Telegram 交流群:https://t.me/BlockBeats_App
Twitter 官方账号:https://twitter.com/BlockBeatsAsia
从技术层面看,中国AI公司走出了一条与算力脱钩的创新路径。当H100这类顶级芯片被切断供应,产业被迫转向优化推理效率与模型架构。DeepSeek-R1以极低推理成本实现前沿性能,Kimi聚焦长上下文与代码能力,Qwen实现全参数量覆盖——这种差异化技术策略,恰恰因硬件限制而加速成熟。开源模式则进一步放大了技术影响力:开发者无需支付API费用即可微调部署,这种开放性与灵活性直接击中了全球创业公司的痛点。
市场选择证明了技术实力的重新平衡。HuggingFace上中国模型占比从1.2%飙升至30%,Qwen下载量超越Llama,这些数据背后是全球开发者用脚投票的结果。当Cursor选择Kimi作为基座模型,当80%美国创业公司使用中国开源模型,这已经与政治立场无关,而是纯粹的技术与经济理性选择——更好的性能、更低的成本、更开放的许可。
更具深层意义的是“双循环”结构的形成:在硬件层面中国仍受制于半导体设备与芯片进口,但在软件层面却通过开源模型反向塑造全球AI基础设施。这种结构暴露了美国管制政策的内部矛盾:一边在硬件层不断加高围墙,一边却无法阻止软件层的技术溢出。五角大楼将供应链风险标签贴给Anthropic,而创业公司却在大量采用中国模型,这种分裂显示政策目标与技术现实已严重脱节。
从更广的视角看,开源正在重塑全球技术权力结构。传统封闭模型如GPT-4依赖算力垄断与API控制,而开源模型通过分布式部署与本地微调,实际上解构了中心化的技术霸权。中国模型在全球的普及,不仅意味着技术替代,更意味着生态位阶的翻转——从技术追随者变为基础设施供给者。
但这也带来新的挑战。开源模型虽消除国界,却可能引发新的标准竞争与知识产权博弈。当中国模型成为全球开发基座,其安全性与价值观嵌入将影响下游应用,这可能触发新的治理争议。同时,硬件依赖仍未解决,半导体设备的管制仍在制约终极算力上限。
最终,这场博弈的核心在于创新模式的竞争:是靠封锁维持技术代差,还是靠开放激发创新活力?当前态势表明,开源生态的渗透力可能远超行政管制的能力范围。中国AI的崛起并非因为避开管制,而是通过压力下的技术突破与生态构建,重新定义了游戏规则。







 0
0