Forum
Forum Finance
Finance
 Specials
Specials
 On-chain Eco
On-chain Eco
 Entry
Entry
 Podcasts
Podcasts
 Activities
Activities
 OPRR
OPRR

Thoughts on zkRollup Hardware Acceleration and zkPOW

By Yanxi Lin, Fox Tech CTO, Shuiyue Kang, Fox Tech CEO
Zero-knowledge proof can provide key functions such as privacy protection, capacity expansion and trust building, which is in line with the spirit of Web3.0. Therefore, its application scenarios spring up in large numbers. At present, ZK small application development difficulty is small, low cost, there are more mature applications; ZK is in its infancy for mid-range applications, and today's technology is sufficient to meet its performance requirements. For large-scale applications, it is still in the early stage, and there are still some technical bottlenecks. It will take some time before it becomes a mature product. Let's start with a brief review of various application scenarios:
Small application scenario
Medium application scenario
Compared with small-scale applications, such applications are more complex and need to be proved. However, compared with small-scale applications, such applications are only multiplied, such as proving correctness in data storage network and ZK-based games.
Large-scale application scenario
zkRollup's Layer2 and zkEVM are the ultimate application of zero-knowledge proof in Web3 to handle state changes brought about by various possibilities in a VM or EVM. This is an exponential increase in complexity compared to small applications, which require a high level of technology, development effort, and are one technology jump away from achieving the desired user experience.
Zero knowledge proof is undoubtedly one of the most innovative technologies in the Web3 field, and it also provides an excellent technical means for building Trustless products. However, as AI has just moved from academia to industry, there are still many problems and challenges in various application scenarios. Fortunately, more and more academic and industrial forces are working in this field. Below we will delve into the different branches of the zk technology tree.
Efficient algorithms and mature development stacks are the core branches
A complete set of zero-knowledge algorithms from research to application needs to go through the stages of theoretical research, development tools construction and specific application development. Efficiency is one of the biggest bottlenecks for zero-knowledge proof application to enter the next stage, including the efficiency of algorithm and the efficiency of development.
In terms of algorithm efficiency, different zero-knowledge proofs use different methods to express the circuit to be proved and are based on different mathematical difficulties. These factors will affect the efficiency of the algorithm. To be specific, important efficiency indicators of a zero-knowledge proof algorithm include proof size, proof time, verification time, etc. At present, a large number of algorithms can achieve a relatively short verification time, and various aggregation technologies can also compress the proof size, while the proof time is the main bottleneck.
Therefore, the design and selection of the project side is very important to the efficiency of the algorithm. Different zero knowledge proof algorithms will form huge differences in complexity. The complexity difference is fully reflected in the specific performance difference when the input is an order of magnitude larger.
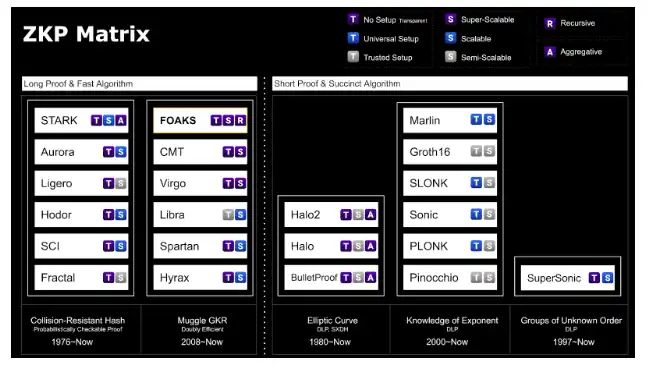
Figure 1: Various zero-knowledge proof algorithms
It is expected that in the future, more teams will invest more research efforts on zero-knowledge proof algorithms to find the algorithm that best meets the project requirements. Layer2 projects like FOX, for example, insist on designing algorithms that reach the theoretical lower bound on the key index of proof time, have linear complexity O(C), and are logarithmic verification time and do not require a trusted setup. This algorithm is well suited to support a scale-up network with no capacity upper limit.
In terms of development, the main reason for the low efficiency of development is the serious lack of relevant development stacks, and the process of converting application scenarios into circuit language and finally into algorithmic proof is quite complicated: some (some) parts of the aforementioned long process need to be abstracted and formed into modular development tools or languages, and maintain compatibility with each other. A complete and rich ZK development stack is the key to breaking the game, allowing developers to focus on their own areas of concern and work together to create a complete ZK application.
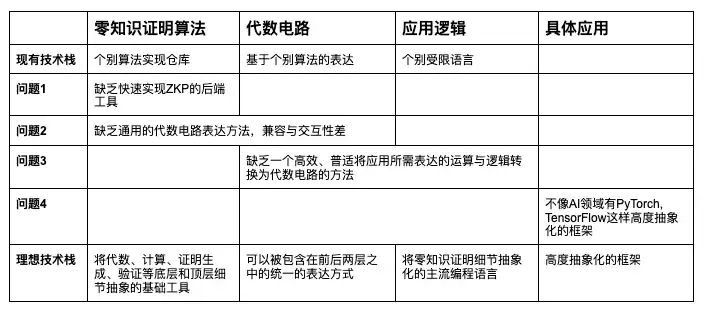
Table 1: Problems with zero-knowledge proof hardware acceleration
Hardware acceleration helps open branches and spread leaves
Hardware acceleration is the key to further improve the efficiency of zero-knowledge proof and make large-scale applications more mature. This involves two questions: which arithmetic can be used to speed things up, and which hardware can be used to speed things up.
For the first problem, the main difference between different zero-knowledge proofs lies in the polynomial commitment methods. Plonk adopted by Matter Labs, Ultra-Plonk adopted by Scroll and other algorithms are polynomial commitment based on KZG. Therefore, Prover involves a lot of FFT calculation and ECC dot MSM operation to generate polynomial and commitment, both of which will bring a lot of computational burden. Specifically, MSMS have the potential to be accelerated by running on multiple threads, but require a lot of memory and are slow even at high parallelism, while FFTS rely heavily on frequent shuffling of the algorithm's run time data, making them difficult to accelerate by distributing load across computing clusters. So it's expensive to accelerate these operations right now.
In addition, STARK developed by Starkware and FOAKS developed by FOX both involve hashing in FRI. There are FFTS, but not in large quantities. Therefore, hardware acceleration can be used to improve the efficiency of these two algorithms.
In terms of hardware, there are three options: GPU, FPGA and ASIC, each with different characteristics:
-GPU:GPU can accelerate parallel computing through certain algorithms. The effect of GPU acceleration depends on the specific algorithm. For example, the FOAKS algorithm used in FOX does not have a large number of FFT and MSM operations, and its ZKEVM design itself contains a large number of parallel computation parts, so the efficiency can be greatly improved by GPU.
-FPGA:FPGA is a programmable integrated circuit, so developers can customize and optimize the miner by targeting the ZK algorithm.
-ASIC:Asics are integrated circuit chips that are specifically tailored for specific uses. However, as ASIC is too customized, it will take more time and cost. Maybe the hardware iteration will gradually move toward ASIC with the increase of the industry scale, but it will not be achieved in one step. Asics could become a mainstream option as specialist hardware vendors such as BitContinental enter the space.
The different characteristics of the three types of hardware also give them different opportunities. GPU in the short term, FPGA in the medium term, ASIC in the long term. As Ethereum moves to PoS, GPU power will flow to networks that can absorb it, and parallel computing friendly networks without a lot of FFTS and MSM will be their first choice. The programmability of FPGA has certain advantages in the medium term, especially in the period when the algorithm changes quickly and the technical route is not stable. The ASIC route means higher costs but greater efficiency gains. In the long run, the big hardware vendors are bound to enter this race and will no doubt choose ASIC as their primary chip type.
zkPOW mechanic design is the icing on the cake
Finally, with complete hardware and software, mechanic design is the last step to make it work and progress steadily. The initial Prover of each zkRollup project is often closer to a traditional centralized service: deployed in the cloud, with the project side sharing the revenue. However, under the narrative of Web3, Prover's future work is bound to develop in the direction of decentralization, and such development also has the following advantages:
There will be more people who can share the computational power of proof generation, and share the benefits bound with the project. This incentive mechanism will allow more local computing power to build and grow the ecosystem together with project owners and foundations.
A good decentralized mechanism will drive more forces to promote technological progress, and allow more experts from all sides to invest in research to continuously improve system efficiency and provide users with better experience.
Decentralized mechanisms will be better able to adapt to the dynamic changes in demand.
However, the decentralization of the proof process has quite a few challenges, such as what kind of consensus the parties should cooperate through after decentralization, which level of the proof process should be distributed decentralized tasks, how to maintain the efficiency of communication and avoid possible attack behavior, etc.
However, some ideal possible solutions have been outlined in the vision of some projects, for example FOX's design includes a zkPOW solution that achieves the following goals:
Computing power is improved by introducing randomness: The calculation of generating proof of zero knowledge is different from that of traditional POW. In the scenario without introducing randomness, the party with the highest computing power will always get the reward of generating proof, which leads to the withdrawal of other parties. After obtaining monopoly, the computing power provider will no longer have the motivation to improve computing power and lose the original intention of decentralization.
Implementation of distribution equity through the introduction of computation income algorithm: An equitable distribution scheme will make the expected revenue of each computation provider proportional to its computation power in the long run, which means that this scheme will allow zkMiner to obtain revenue by investing computation power, as in the PoW mechanism, and make it difficult for ZkMiner to obtain excess incentive revenue by illegal means. In the long run, a fair computation income algorithm can also ensure the stability of the number of computation providers in the system, and it also means higher anti-attack capability.
In FOX's zkPOW design, participants who submit their proofs within a time window after the first proof is submitted can get different proportions of incentives. Meanwhile, randomness is introduced to make the contents of each proof submitted different, which means that a complete proof calculation must be performed behind each proof submitted. Through carefully designed proportional distribution, the expected income of each participant will be proportional to its computing power, which will generate positive incentives for each participant to improve computing efficiency. Finally, all users of the project will benefit from this and enjoy safer, faster and cheaper zkRollup services.
Welcome to join the official BlockBeats community:
Telegram Subscription Group: https://t.me/theblockbeats
Telegram Discussion Group: https://t.me/BlockBeats_App
Official Twitter Account: https://twitter.com/BlockBeatsAsia